
Build an event management practice that is situated in the larger service management environment. Purposefully choose valuable events to track and predefine their associated actions to cut down on data clutter.
Our Advice
Critical Insight
Event management is useless in isolation. The goals come from the pain points of other ITSM practices. Build handoffs to other service management practices to drive the proper action when an event is detected.
Impact and Result
Create a repeatable framework to define monitored events, their root cause, and their associated action. Record your monitored events in a catalog to stay organized.
Engineer Your Event Management Process Research & Tools
Besides the small introduction, subscribers and consulting clients within this management domain have access to:
1. Engineer Your Event Management Deck – A step-by-step document that walks you through how to choose meaningful, monitored events to track and action.
Engineer your event management practice with tracked events informed by the business impact of the related systems, applications, and services. This storyboard will help you properly define and catalog events so you can properly respond when alerted.
- Engineer Your Event Management Process – Phases 1-3
2. Event Management Cookbook – A guide to help you walk through every step of scoping event management and defining every event you track in your IT environment.
Use this tool to define your workflow for adding new events to track. This cookbook includes the considerations you need to include for every tracked event as well as the roles and responsibilities of those involved with event management.
- Event Management Cookbook
3. Event Management Catalog – Using the Event Management Cookbook as a guide, record all your tracked events in the Event Management Catalog.
Use this tool to record your tracked events and alerts in one place. This catalog allows you to record the rationale, root-cause, action, and data governance for all your monitored events.
- Event Management Catalog
4. Event Management Workflow – Define your event management handoffs to other service management practices.
Use this template to help define your event management handoffs to other service management practices including change management, incident management, and problem management.
- Event Management Workflow (Visio)
- Event Management Workflow (PDF)
5. Event Management Roadmap – Implement and continually improve upon your event management practice.
Use this tool to implement and continually improve upon your event management process. Record, prioritize, and assign your action items from the event management blueprint.
- Event Management Roadmap
Workshop: Engineer Your Event Management Process
Workshops offer an easy way to accelerate your project. If you are unable to do the project yourself, and a Guided Implementation isn't enough, we offer low-cost delivery of our project workshops. We take you through every phase of your project and ensure that you have a roadmap in place to complete your project successfully.
1 Situate Event Management in Your Service Management Environment
The Purpose
Determine goals and challenges for event management and set the scope to business-critical systems.
Key Benefits Achieved
Defined system scope of Event Management
Roles and responsibilities defined
Activities
1.1 List your goals and challenges
1.2 Monitoring and event management RACI
1.3 Abbreviated business impact analysis
Outputs
Event Management RACI (as part of the Event Management Cookbook)
Abbreviated BIA (as part of the Event Management Cookbook)
2 Define Your Event Management Scope
The Purpose
Define your in-scope configuration items and their operational conditions
Key Benefits Achieved
Operational conditions, related CIs and dependencies, and CI thresholds defined
Activities
2.1 Define operational conditions for systems
2.2 Define related CIs and dependencies
2.3 Define conditions for CIs
2.4 Perform root-cause analysis for complex condition relationships
2.5 Set thresholds for CIs
Outputs
Event Management Catalog
3 Define Thresholds and Actions
The Purpose
Pre-define actions for every monitored event
Key Benefits Achieved
Thresholds and actions tied to each monitored event
Activities
3.1 Set thresholds to monitor
3.2 Add actions and handoffs to event management
Outputs
Event Catalog
Event Management Workflows
4 Start Monitoring and Implement Event Management
The Purpose
Effectively implement event management
Key Benefits Achieved
Establish an event management roadmap for implementation and continual improvement
Activities
4.1 Define your data policy for event management
4.2 Identify areas for improvement and establish an implementation plan
Outputs
Event Catalog
Event Management Roadmap
Further reading
Engineer Your Event Management Process
Track monitored events purposefully and respond effectively.
EXECUTIVE BRIEF
Analyst Perspective
Event management is useless in isolation.
Event management creates no value when implemented in isolation. However, that does not mean event management is not valuable overall. It must simply be integrated properly in the service management environment to inform and drive the appropriate actions.
Every step of engineering event management, from choosing which events to monitor to actioning the events when they are detected, is a purposeful and explicit activity. Ensuring that event management has open lines of communication and actions tied to related practices (e.g. problem, incident, and change) allows efficient action when needed.
Catalog your monitored events using a standardized framework to allow you to know:
- The value of tracking the event.
- The impact when the event is detected.
- The appropriate, right-sized reaction when the event is detected.
- The tool(s) involved in tracking the event.
Properly engineering event management allows you to effectively monitor and understand your IT environment and bolster the proactivity of the related service management practices.

Benedict Chang
Research Analyst, Infrastructure & Operations
Info-Tech Research Group
Executive Summary
Your Challenge
Strive for proactivity. Implement event management to reduce response times of technical teams to solve (potential) incidents when system performance degrades.
Build an integrated event management practice where developers, service desk, and operations can all rely on event logs and metrics.
Define the scope of event management including the systems to track, their operational conditions, related configuration items (CIs), and associated actions of the tracked events.
Common Obstacles
Managed services, subscription services, and cloud services have reduced the traditional visibility of on- premises tools.
System(s) complexity and integration with the above services has increased, making true cause and effect difficult to ascertain.
Info-Tech’s Approach
Clearly define a limited number of operational objectives that may benefit from event management.
Focus only on the key systems whose value is worth the effort and expense of implementing event management.
Understand what event information is available from the CIs of those systems and map those against your operational objectives.
Write a data retention policy that balances operational, audit, and debugging needs against cost and data security needs.
Info-Tech Insight
More is NOT better. Even in an AI-enabled world, every event must be collected with a specific objective in mind. Defining the purpose of each tracked event will cut down on data clutter and response time when events are detected.
Your challenge
This research is designed to help organizations who are facing these challenges or looking to:
- Build an event management practice that is situated in the larger service management environment.
- Purposefully choose events and to track as well as their related actions based on business-critical systems, their conditions, and their related CIs.
- Cut down on the clutter of current events tracked.
- Create a framework to add new events when new systems are onboarded.
33%
In 2020, 33% of organizations listed network monitoring as their number one priority for network spending. 27% of organizations listed network monitoring infrastructure as their number two priority.
Source: EMA, 2020; n=350
Common obstacles
These barriers make this challenge difficult to address for many organizations:
- Many organizations have multiple tools across multiple teams and departments that track the current state of infrastructure, making it difficult to consolidate event management into a single practice.
- Managed services, subscription services, and cloud services have reduced the traditional visibility of on-premises tools
- System(s) complexity and integration with the above services has increased, making true cause and effect difficult to ascertain.
Build event management to bring value to the business
33%
33% of all IT organizations reported that end users detected and reported incidents before the network operations team was aware of them.
Source: EMA, 2020; n=350
64%
64% of enterprises use 4-10 monitoring tools to troubleshoot their network.
Source: EMA, 2020; n=350
Info-Tech’s approach
Choose your events purposefully to avoid drowning in data.
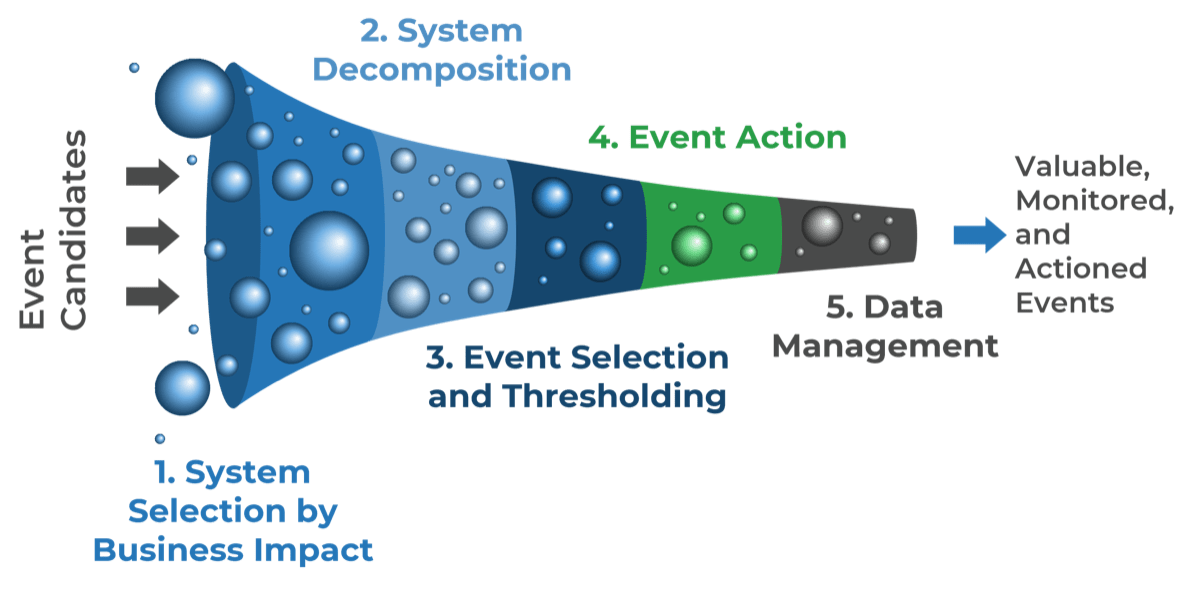
The Info-Tech difference:
- Start with a list of your most business-critical systems instead of data points to measure.
- Decompose your business-critical systems into their configuration items. This gives you a starting point for choosing what to measure.
- Choose your events and label them as notifications, warnings, or exceptions. Choose the relevant thresholds for each CI.
- Have a pre-defined action tied to each event. That action could be to log the datapoint for a report or to open an incident or problem ticket.
- With your event catalog defined, choose how you will measure the events and where to store the data.
Event management is useless in isolation
Define how event management informs other management practices.
Logging, Archiving, and Metrics
Monitoring and event management can be used to establish and analyze your baseline. The more you know about your system baselines, the easier it will be to detect exceptions.
Change Management
Events can inform needed changes to stay compliant or to resolve incidents and problems. However, it doesn’t mean that changes can be implemented without the proper authorization.
Automatic Resolution
The best use case for event management is to detect and resolve incidents and problems before end users or IT are even aware.
Incident Management
Events sitting in isolation are useless if there isn’t an effective way to pass potential tickets off to incident management to mitigate and resolve.
Problem Management
Events can identify problems before they become incidents. However, you must establish proper data logging to inform problem prioritization and actioning.
Info-Tech’s methodology for Engineering Your Event Management Process
| 1. Situate Event Management in Your Service Management Environment | 2. Define Your Monitoring Thresholds and Accompanying Actions | 3. Start Monitoring and Implement Event Management | |
|
Phase Steps |
1.1 Set Operational and Informational Goals 1.2 Scope Monitoring and States of Interest |
2.1 Define Conditions and Related CIs 2.2 Set Monitoring Thresholds and Alerts 2.3 Action Your Events |
3.1 Define Your Data Policy 3.2 Define Future State |
|
Event Cookbook Event Catalog |
|||
|
Phase Outcomes |
Monitoring and Event Management RACI Abbreviated BIA |
Event Workflow |
Event Management Roadmap |
Insight summary
Event management is useless in isolation.
The goals come from the pain points of other ITSM practices. Build handoffs to other service management practices to drive the proper action when an event is detected.
Start with business intent.
Trying to organize a catalog of events is difficult when working from the bottom up. Start with the business drivers of event management to keep the scope manageable.
Keep your signal-to-noise ratio as high as possible.
Defining tracked events with their known conditions, root cause, and associated actions allows you to be proactive when events occur.
Improve slowly over time.
Start small if need be. It is better and easier to track a few items with proper actions than to try to analyze events as they occur.
More is NOT better. Avoid drowning in data.
Even in an AI-enabled world, every event must be collected with a specific objective in mind. Defining the purpose of each tracked event will cut down on data clutter and response time when events are detected.
Add correlations in event management to avoid false positives.
Supplement the predictive value of a single event by aggregating it with other events.
Blueprint deliverables
Each step of this blueprint is accompanied by supporting deliverables to help you accomplish your goals:
Key deliverable:

Event Management Cookbook
Use the framework in the Event Management Cookbook to populate your event catalog with properly tracked and actioned events.

Event Management RACI
Define the roles and responsibilities needed in event management.
Event Management Workflow
Define the lifecycle and handoffs for event management.
Event Catalog
Consolidate and organize your tracked events.
Event Roadmap
Roadmap your initiatives for future improvement.
Blueprint benefits
IT Benefits
- Provide a mechanism to compare operating performance against design standards and SLAs.
- Allow for early detection of incidents and escalations.
- Promote timely actions and ensure proper communications.
- Provide an entry point for the execution of service management activities.
- Enable automation activity to be monitored by exception
- Provide a basis for service assurance, reporting and service improvements.
Business Benefits
- Less overall downtime via earlier detection and resolution of incidents.
- Better visibility into SLA performance for supplied services.
- Better visibility and reporting between IT and the business.
- Better real-time and overall understanding of the IT environment.
Case Study
An event management script helped one company get in front of support calls.
INDUSTRY - Research and Advisory
SOURCE - Anonymous Interview
Challenge
One staff member’s workstation had been infected with a virus that was probing the network with a wide variety of usernames and passwords, trying to find an entry point. Along with the obvious security threat, there existed the more mundane concern that workers occasionally found themselves locked out of their machine and needed to contact the service desk to regain access.
Solution
The system administrator wrote a script that runs hourly to see if there is a problem with an individual’s workstation. The script records the computer's name, the user involved, the reason for the password lockout, and the number of bad login attempts. If the IT technician on duty notices a greater than normal volume of bad password attempts coming from a single account, they will reach out to the account holder and inquire about potential issues.
Results
The IT department has successfully proactively managed two distinct but related problems: first, they have prevented several instances of unplanned work by reaching out to potential lockouts before they receive an incident report. They have also successfully leveraged event management to probe for indicators of a security threat before there is a breach.
Info-Tech offers various levels of support to best suit your needs
DIY Toolkit
“Our team has already made this critical project a priority, and we have the time and capability, but some guidance along the way would be helpful.”
Guided Implementation
“Our team knows that we need to fix a process, but we need assistance to determine where to focus. Some check-ins along the way would help keep us on track.”
Workshop
“We need to hit the ground running and get this project kicked off immediately. Our team has the ability to take this over once we get a framework and strategy in place.”
Consulting
“Our team does not have the time or the knowledge to take this project on. We need assistance through the entirety of this project.”
Diagnostics and consistent frameworks used throughout all four options
Guided Implementation
What does a typical GI on this topic look like?
| Phase 1 | Phase 2 | Phase 3 |
|---|
|
Call #1: Scope requirements, objectives, and your specific challenges. |
Call #2: Introduce the Cookbook and explore the business impact analysis. |
Call #4: Define operational conditions. |
Call #6: Define actions and related practices. |
Call #8: Identify and prioritize improvements. |
|
Call #3: Define system scope and related CIs/ dependencies. |
Call #5: Define thresholds and alerts. |
Call #7: Define data policy. |
A Guided Implementation (GI) is a series of calls with an Info-Tech analyst to help implement our best practices in your organization.
A typical GI is between 6 to 12 calls over the course of 4 to 6 months.
Workshop Overview
Contact your account representative for more information.
workshops@infotech.com 1-888-670-8889
| Day 1 | Day 2 | Day 3 | Day 4 | Day 5 | |
|---|---|---|---|---|---|
| Situate Event Management in Your Service Management Environment | Define Your Event Management Scope | Define Thresholds and Actions | Start Monitoring and Implement Event Management | Next Steps and Wrap-Up (offsite) | |
|
Activities |
1.1 3.1 Set Thresholds to Monitor 3.2 Add Actions and Handoffs to Event Management Introductions 1.2 Operational and Informational Goals and Challenges 1.3 Event Management Scope 1.4 Roles and Responsibilities |
2.1 Define Operational Conditions for Systems 2.2 Define Related CIs and Dependencies 2.3 Define Conditions for CIs 2.4 Perform Root-Cause Analysis for Complex Condition Relationships 2.4 Set Thresholds for CIs |
3.1 Set Thresholds to Monitor 3.2 Add Actions and Handoffs to Event Management |
4.1 Define Your Data Policy for Event Management 4.2 Identify Areas for Improvement and Future Steps 4.3 Summarize Workshop |
5.1 Complete In-Progress Deliverables From Previous Four Days 5.2 Set Up Review Time for Workshop Deliverables and to Discuss Next Steps |
| Deliverables |
|
|
|
|
|
Phase 1
Situate Event Management in Your Service Management Environment
| Phase 1 | Phase 2 | Phase 3 |
|---|---|---|
|
1.1 Set Operational and Informational Goals |
2.1 Define Conditions and Related CIs |
3.1 Define Your Data Policy |
Engineer Your Event Management Process
This phase will walk you through the following activities:
1.1.1 List your goals and challenges
1.1.2 Build a RACI chart for event management
1.2.1 Set your scope using business impact
This phase involves the following participants:
Infrastructure management team
IT managers
Step 1.1
Set Operational and Informational Goals
Activities
1.1.1 List your goals and challenges
1.1.2 Build a RACI chart for event management
Situate Event Management in Your Service Management Environment
This step will walk you through the following activities:
Set the overall scope of event management by defining the governing goals. You will also define who is involved in event management as well as their responsibilities.
This step involves the following participants:
Infrastructure management team
IT managers
Outcomes of this step
Define the goals and challenges of event management as well as their data proxies.
Have a RACI matrix to define roles and responsibilities in event management.
Situate event management among related service management practices
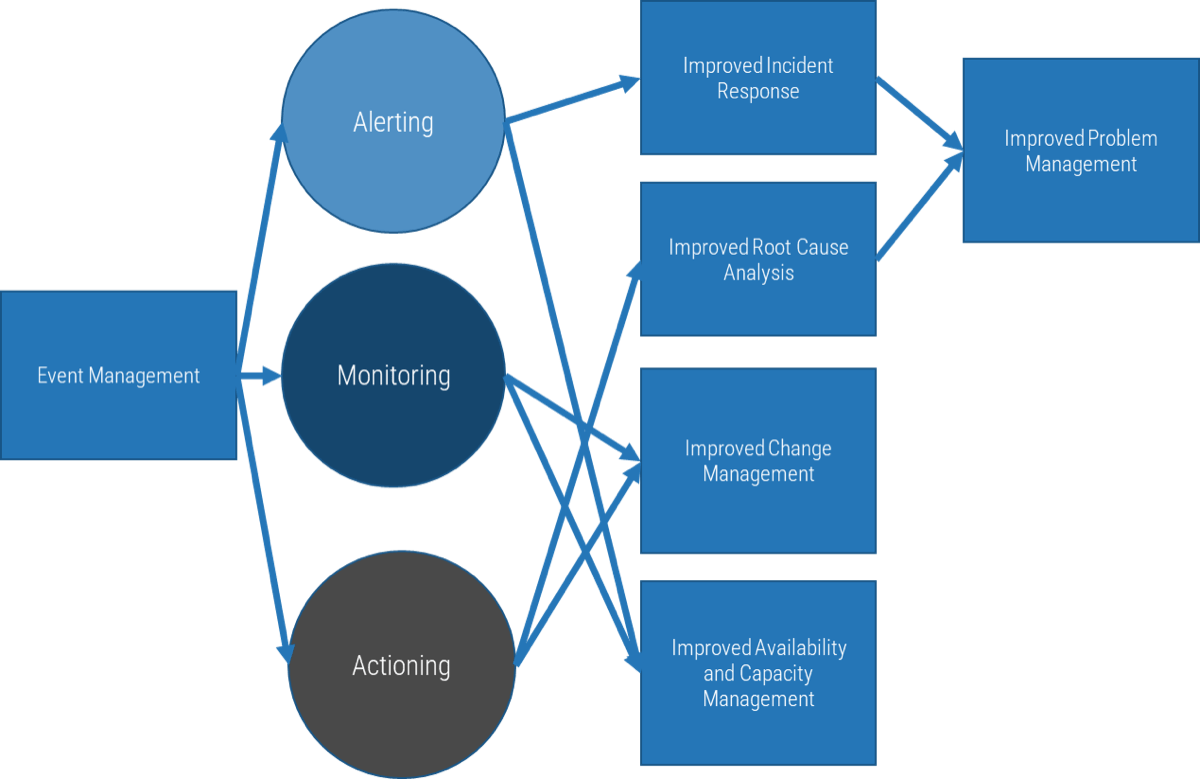
Event management needs to interact with the following service management practices:
- Incident Management – Event management can provide early detection and/or prevention of incidents.
- Availability and Capacity Management – Event management helps detect issues with availability and capacity before they become an incident.
- Problem Management – The data captured in event management can aid in easier detection of root causes of problems.
- Change Management – Event management can function as the rationale behind needed changes to fix problems and incidents.
Consider both operational and informational goals for event management
Event management may log real-time data for operational goals and non-real time data for informational goals
|
Event Management |
||||
|---|---|---|---|---|
|
Operational Goals (real-time) |
Informational Goals (non-real time) |
|||
|
Incident Response & Prevention |
Availability Scaling |
Availability Scaling |
Modeling and Testing |
Investigation/ Compliance |
- Knowing what the outcomes are expected to achieve helps with the design of that process.
- A process targeted to fewer outcomes will generally be less complex, easier to adhere to, and ultimately, more successful than one targeted to many goals.
- Iterate for improvement.
1.1.1 List your goals and challenges
Gather a diverse group of IT staff in a room with a whiteboard.
Have each participant write down their top five specific outcomes they want from improved event management.
Consolidate similar ideas.
Prioritize the goals.
Record these goals in your Event Management Cookbook.
| Priority | Example Goals |
|---|---|
| 1 | Reduce response time for incidents |
| 2 | Improve audit compliance |
| 3 | Improve risk analysis |
| 4 | Improve forecasting for resource acquisition |
| 5 | More accurate RCAs |
Input
- Pain points
Output
- Prioritized list of goals and outcomes
Materials
- Whiteboard/flip charts
- Sticky notes
Participants
- Infrastructure management team
- IT managers
Event management is a group effort
- Event management needs to involve multiple other service management practices and service management roles to be effective.
- Consider the roles to the right to see how event management can fit into your environment.
Infrastructure Team
The infrastructure team is accountable for deciding which events to track, how to track, and how to action the events when detected.
Service Desk
The service desk may respond to events that are indicative of incidents. Setting a root cause for events allows for quicker troubleshooting, diagnosis, and resolution of the incident.
Problem and Change Management
Problem and change management may be involved with certain event alerts as the resultant action could be to investigate the root cause of the alert (problem management) or build and approve a change to resolve the problem (change management).
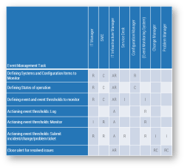
1.1.2 Build a RACI chart for event management
- As a group, complete the RACI chart using the template to the right. RACI stands for the following:
- Responsible. The person doing the work.
- Accountable. The person who ensures the work is done.
- Consulted. Two-way communication.
- Informed. One-way communication
- There must be one and only one accountable person for each task. There must also be at least one responsible person. Depending on the use case, RACI letters may be combined (e.g. AR means the person who ensures the work is complete but also the person doing the work).
- Start with defining the roles in the first row in your own environment.
- Look at the tasks on the first column and modify/add/subtract tasks as necessary.
- Populate the RACI chart as necessary.
Download the Event Management Cookbook
| Event Management Task | IT Manager | SME | IT Infrastructure Manager | Service Desk | Configuration Manager | (Event Monitoring System) | Change Manager | Problem Manager |
| Defining systems and configuration items to monitor | R | C | AR | R | ||||
| Defining states of operation | R | C | AR | C | ||||
| Defining event and event thresholds to monitor | R | C | AR | I | I | |||
| Actioning event thresholds: Log | A | R | ||||||
| Actioning event thresholds: Monitor | I | R | A | R | ||||
| Actioning event thresholds: Submit incident/change/problem ticket | R | R | A | R | R | I | I | |
| Close alert for resolved issues | AR | RC | RC | |||||
Step 1.2
Scope Monitoring and Event Management Using Business Impact
Activities
1.2.1 Set your scope using business impact
Situate Event Management in Your Service Management Environment
This step will walk you through the following activities:
- Set your scope of event management using an abbreviated business impact analysis.
This step involves the following participants:
- Infrastructure manager
- IT managers
Outcomes of this step
- List of systems, services, and applications to monitor.
Use the business impact of your systems to set the scope of monitoring
Picking events to track and action is difficult. Start with your most important systems according to business impact.
- Business impact can be determined by how costly system downtime is. This could be a financial impact ($/hour of downtime) or goodwill impact (internal/external stakeholders affected).
- Use business impact to determine the rating of a system by Tier (Gold, Silver, or Bronze):
- GOLD: Mission-critical services. An outage is catastrophic in terms of cost or public image/goodwill. Example: trading software at a financial institution.
- SILVER: Important to daily operations but not mission critical. Example: email services at any large organization.
- BRONZE: Loss of these services is an inconvenience more than anything, though they do serve a purpose and will be missed if they are never brought back online. Example: ancient fax machines.
- Align a list of systems to track with your previously selected goals for event management to determine WHY you need to track that system. Tracking the system could inform critical SLAs (performance/uptime), vulnerability, compliance obligations, or simply system condition.
More is not better
Tracking too many events across too many tools could decrease your responsiveness to incidents. Start tracking only what is actionable to keep the signal-to-noise ratio of events as high as possible.
% of Incidents Reported by End Users Before Being Recognized by IT Operations
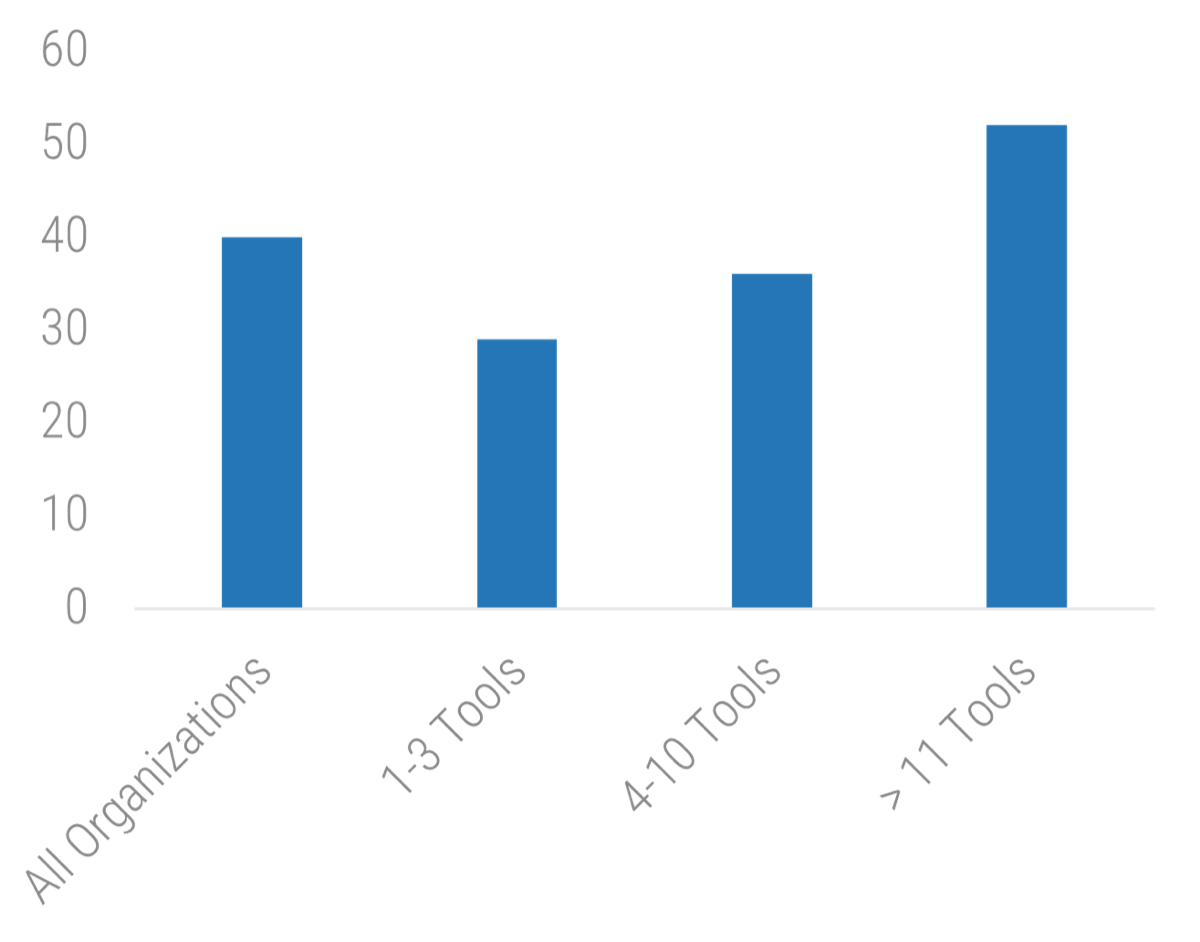 11 Tools: 52">
11 Tools: 52">
Source: Riverbed, 2016
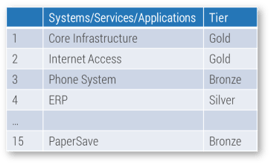
1.2.1 Set your scope using business impact
Collating an exhaustive list of applications and services is onerous. Start small, with a subset of systems.
- Gather a diverse group of IT staff and end users in a room with a whiteboard.
- List 10-15 systems and services. Solicit feedback from the group. Questions to ask:
- What services do you regularly use? What do you see others using?
(End users) - Which service comprises the greatest number of service calls? (IT)
- What services are the most critical for business operations? (Everybody)
- What is the cost of downtime (financial and goodwill) for these systems? (Business)
- How does monitoring these systems align with your goals set in Step 1.1?
- What services do you regularly use? What do you see others using?
- Assign an importance to each of these systems from Gold (most important) to Bronze (least important).
- Record these systems in your Event Management Cookbook.
| Systems/Services/Applications | Tier | |
|---|---|---|
| 1 | Core Infrastructure | Gold |
| 2 | Internet Access | Gold |
| 3 | Public-Facing Website | Gold |
| 4 | ERP | Silver |
| … | ||
| 15 | PaperSave | Bronze |
Include a variety of services in your analysis
It might be tempting to jump ahead and preselect important applications. However, even if an application is not on the top 10 list, it may have cross-dependencies that make it more valuable than originally thought.
For a more comprehensive BIA, see Create a Right-Sized Disaster Recovery Plan
Download the Event Management Cookbook
Phase 2
Define Your Monitoring Thresholds and Accompanying Actions
| Phase 1 | Phase 2 | Phase 3 |
|---|---|---|
1.1 Set Operational and Informational Goals | 2.1 Define Conditions and Related CIs | 3.1 Define Your Data Policy |
Engineer Your Event Management Process
This phase will walk you through the following activities:
- 2.1.1 Define performance conditions
- 2.1.2 Decompose services into Related CIs
- 2.2.1 Verify your CI conditions with a root-cause analysis
- 2.2.2 Set thresholds for your events
- 2.3.1 Set actions for your thresholds
- 2.3.2 Build your event management workflow
This phase involves the following participants:
- Business system owners
- Infrastructure manager
- IT managers
Step 2.1
Define Conditions and Related CIs
Activities
2.1.1 Define performance conditions
2.1.2 Decompose services into related CIs
Define Your Monitoring Thresholds and Accompanying Actions
This step will walk you through the following activities:
For each monitored system, define the conditions of interest and related CIs.
This step involves the following participants:
Business system owners
Infrastructure manager
IT managers
Outcomes of this step
List of conditions of interest and related CIs for each monitored system.
Consider the state of the system that is of concern to you
Events present a snapshot of the state of a system. To determine which events you want to monitor, you need to consider what system state(s) of importance.
- Systems can be in one of three states:
- Up
- Down
- Degraded
- What do these states mean for each of your systems chosen in your BIA?
- Up and Down are self-explanatory and a good place to start.
- However, degraded systems are indicative that one or more component systems of an overarching system has failed. You must uncover the nature of such a failure, which requires more sophisticated monitoring.
2.1.1 Define system states of greatest importance for each of your systems
- With the system business owners and compliance officers in the room, list the performance states of your systems chosen in your BIA.
- If you have too many systems listed, start only with the Gold Systems.
- Use the following proof approaches if needed:
- Positive Proof Approach – every system when it has certain technical and business performance expectations. You can use these as a baseline.
- Negative Proof Approach – users know when systems are not performing. Leverage incident data and end-user feedback to determine failed or degraded system states and work backwards.
- Focus on the end-user facing states.
- Record your critical system states in the Event Management Cookbook.
- Use these states in the next several activities and translate them into measurable infrastructure metrics.
Input
- Results of business impact analysis
Output
- Critical system states
Materials
- Whiteboard/flip charts
- Sticky notes
- Markers
Participants
- Infrastructure manager
- Business system owners
2.1.2 Decompose services into relevant CIs
Define your system dependencies to help find root causes of degraded systems.
- For each of your systems identified in your BIA, list the relevant CIs.
- Identify dependencies and relationship of those CIs with other CIs (linkages and dependencies).
- Starting with the Up/Down conditions for your Gold systems, list the conditions of the CIs that would lead to the condition of the system. This may be a 1:1 relationship (e.g. Core Switches down = Core Infrastructure down) or a many:1 relationship (some virtualization hosts + load balancers down = Core Infrastructure down). You do not need to define specific thresholds yet. Focus on conditions for the CIs.
- Repeat step 3 with Degraded conditions.
- Repeat step 3 and 4 with Silver and Bronze systems.
- Record the results in the Event Management Cookbook.
Core Infrastructure Example

Step 2.2
Set Monitoring Thresholds and Alerts
Activities
2.2.1 Verify your CI conditions with a root-cause analysis
2.2.2 Set thresholds for your events
Define Your Monitoring Thresholds and Accompanying Actions
This step will walk you through the following activities:
Set monitoring thresholds for each CI related to each condition of interest.
This step involves the following participants:
Business system managers
Infrastructure manager
IT managers
Service desk manager
Outcomes of this step
List of events to track along with their root cause.
Event management will involve a significant number of alerts
Separate the serious from trivial to keep the signal-to-noise ratio high.
Set your own thresholds
You must set your own monitoring criteria based on operational needs. Events triggering an action should be reviewed via an assessment of the potential project and associated risks.
Consider the four general signal types to help define your tracked events
Latency – time to respond
Examples:
- Web server – time to complete request
- Network – roundtrip ping time
- Storage – read/write queue times
Traffic – amount of activity per unit time
Web sever – how many pages per minute
Network – Mbps
Storage – I/O read/writes per sec
Errors – internally tracked erratic behaviors
Web Server – page load failures
Network – packets dropped
Storage – disk errors
Saturation – consumption compared to theoretical maximum
Web Server – % load
Network – % utilization
Storage – % full
2.2.1 Verify your CI conditions with a root-cause analysis
RCAs postulate why systems go down; use the RCA to inform yourself of the events leading up to the system going down.
- Gather a diverse group of IT staff in a room with a whiteboard.
- Pick a complex example of a system condition (many:1 correlation) that has considerable data associated with it (e.g. recorded events, problem tickets).
- Speculate on the most likely precursor conditions. For example, if a related CI fails or is degraded, which metrics would you likely see before the failure?
- If something failed, imagine what you’d most likely see before the failure.
- Extend that timeline backward as far as you can be reasonably confident.
- Pick a value for that event.
- Write out your logic flow from event recognition to occurrence.
- Once satisfied, program the alert and ideally test in a non-prod environment.
Public Website Example
| Dependency | CIs | Tool | Metrics |
|---|---|---|---|
| ISP | WAN | SNMP Traps | Latency |
| Telemetry | Packet Loss | ||
| SNMP Pooling | Jitter | ||
| Network Performance | Web Server | Response Time | |
| Connection Stage Errors | |||
| Web Server | Web Page | DOM Load Time | |
| Performance | |||
| Page Load Time | |||
Let your CIs help you
At the end of the day, most of us can only monitor what our systems let us. Some (like Exchange Servers) offer a crippling number of parameters to choose from. Other (like MPLS) connections are opaque black boxes giving up only the barest of information. The metrics you choose are largely governed by the art of the possible.
Case Study
Exhaustive RCAs proved that 54% of issues were not caused by storage.
![]()
INDUSTRY - Enterprise IT
SOURCE - ESG, 2017
Challenge
Despite a laser focus on building nothing but all-flash storage arrays, Nimble continued to field a dizzying number of support calls.
Variability and complexity across infrastructure, applications, and configurations – each customer install being ever so slightly different – meant that the problem of customer downtime seemed inescapable.
Solution
Nimble embedded thousands of sensors into its arrays, both at a hardware level and in the code. Thousands of sensors per array multiplied by 7,500 customers meant millions of data points per second.
This data was then analyzed against 12,000 anonymized app-data gap-related incidents.
Patterns began to emerge, ones that persisted across complex customer/array/configuration combinations.
These patterns were turned into signatures, then acted on.
Results
54% of app-data gap related incidents were in fact related to non-storage factors! Sub-optimal configuration, bad practices, poor integration with other systems, and even VM or hosts were at the root cause of over half of reported incidents.
Establishing that your system is working fine is more than IT best practice – by quickly eliminating potential options the right team can get working on the right system faster thus restoring the service more quickly.
Gain an even higher SNR with event correlation
Filtering:
Event data determined to be of minimal predictive value is shunted aside.
Aggregation:
De-duplication and combination of similar events to trigger a response based on the number or value of events, rather than for individual events.
Masking:
Ignoring events that occur downstream of a known failed system. Relies on accurate models of system relationships.
Triggering:
Initiating the appropriate response. This could be simple logging, any of the exception event responses, an alert requiring human intervention, or a pre-programmed script.
2.2.2 Set thresholds for your events
If the event management team toggles the threshold for an alert too low (e.g. one is generated every time a CPU load reaches 60% capacity), they will generate too many false positives and create far too much work for themselves, generating alert fatigue. If they go the other direction and set their thresholds too high, there will be too many false negatives – problems will slip through and cause future disruptions.
- Take your list of RCAs from the previous activity and conduct an activity with the group. The goal of the exercise is to produce the predictive event values that confidently predict an imminent event.
- Questions to ask:
- What are some benign signs of this incident?
- Is there something we could have monitored that would have alerted us to this issue before an incident occurred?
- Should anyone have noticed this problem? Who? Why? How?
- Go through this for each of the problems identified and discuss thresholds. When complete, include the information in the Event Management Catalog.
Public Website Example
| Dependency | Metrics | Threshold |
| Network Performance | Latency | 150ms |
| Packet Loss | 10% | |
| Jitter | >1ms | |
| Web Server | Response Time | 750ms |
| Performance | ||
| Connection Stage Errors | 2 | |
| Web Page Performance | DOM Load time | 1100ms |
| Page Load time | 1200ms | |
Step 2.3
Action Your Events
Activities
2.3.1 Set actions for your thresholds
2.3.2 Build your event management workflow
Define Your Monitoring Thresholds and Associated Actions
This step will walk you through the following activities:
With your list of tracked events from the previous step, build associated actions and define the handoff from event management to related practices.
This step involves the following participants:
Event management team
Infrastructure team
Change manager
Problem manager
Incident manager
Outcomes of this step
Event management workflow
Set actions for your thresholds
For each of your thresholds, you will need an action tied to the event.
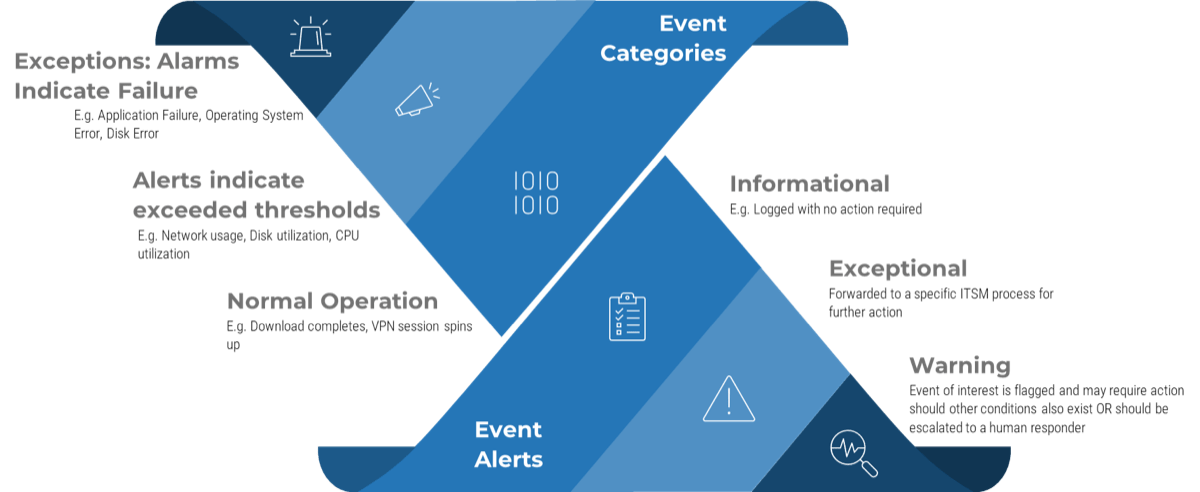
- Review the event alert types:
- Informational
- Warning
- Exception
- Your detected events will require one of the following actions if detected.
- Unactioned events will lead to a poor signal-to-noise ratio of data, which ultimately leads to confusion in the detection of the event and decreased response effectiveness.
Event Logged
For informational alerts, log the event for future analysis.
Automated Resolution
For a warning or exception event or a set of events with a well-known root cause, you may have an automated resolution tied to detection.
Human Intervention
For warnings and exceptions, human intervention may be needed. This could include manual monitoring or a handoff to incident, change, or problem management.
2.3.1 Set actions for your thresholds
Alerts generated by event management are useful for many different ITSM practitioners.
- With the chosen thresholds at hand, analyze the alerts and determine if they require immediate action or if they can be logged for later analysis.
- Questions to ask:
- What kind of response does this event warrant?
- How could we improve our event management process?
- What event alerts would have helped us with root-cause analysis in the past?
- Record the results in the Event Management Catalog.
Public Website Example
| Outcome | Metrics | Threshold | Response (s) | |
|---|---|---|---|---|
| Network Performance | Latency | 150ms | Problem Management | Tag to Problem Ticket 1701 |
| Web Page Performance | DOM Load time | 1100ms | Change Management | |
Download the Event Management Catalog
Input
- List of events generated by event management
Output
- Action plan for various events as they occur
Materials
- Whiteboard/flip charts
- Pens
- Paper
Participants
- Event Management Team
- Infrastructure Team
- Change Manager
- Problem Manager
- Incident Manager
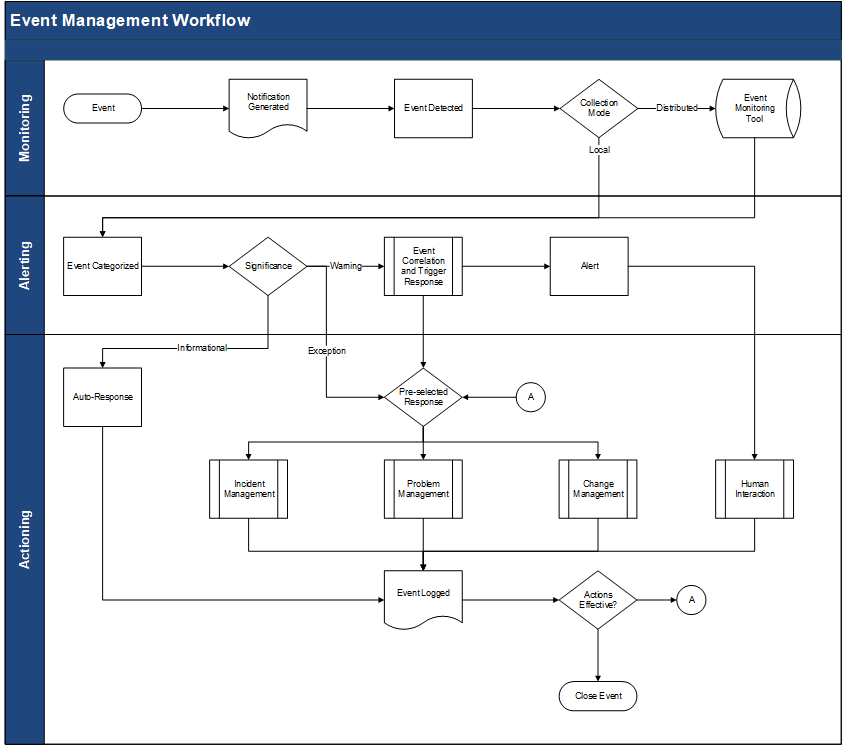
2.3.2 Build your event management workflow
- As a group, discuss your high-level monitoring, alerting, and actioning processes.
- Define handoff processes to incident, problem, and change management. If necessary, open your incident, problem, and change workflows and discuss how the event can further pass onto those practices. Discuss the examples below:
- Incident Management: Who is responsible for opening the incident ticket? Can the incident ticket be automated and templated?
- Change Management: Who is responsible for opening an RFC? Who will approve the RFC? Can it be a pre-approved change?
- Problem Management : Who is responsible for opening the problem ticket? How can the event data be useful in the problem management process?
- Use and modify the example workflow as needed by downloading the Event Management Workflow.
Example Workflow:
Common datapoints to capture for each event
Data captured will help related service management practices in different ways. Consider what you will need to record for each event.
- Think of the practice you will be handing the event to. For example, if you’re handing the event off to incident or problem management, data captured will have to help in root-cause analysis to find and execute the right solution. If you’re passing the event off to change management, you may need information to capture the rationale of the change.
- Knowing the driver for the data can help you define the right data captured for every event.
- Consider the data points below for your events:
|
Data Fields |
|
|---|---|
|
Device |
Date/time |
|
Component |
Parameters in exception |
|
Type of failure |
Value |
Start Monitoring and Implement Event Management
| Phase 1 | Phase 2 | Phase 3 |
|---|---|---|
1.1 Set Operational and Informational Goals | 2.1 Define Conditions and Related CIs | 3.1 Define Your Data Policy |
Engineer Your Event Management Process
This phase will walk you through the following activities:
3.1.1 Define data policy needs
3.2.1 Build your roadmap
This phase involves the following participants:
Business system owners
Infrastructure manager
IT managers
Step 3.1
Define Your Data Policy
Activities
3.1.1 Define data policy needs
Start Monitoring and Implement Event Management
This step will walk you through the following activities:
Your overall goals from Phase 1 will help define your data retention needs. Document these policy statements in a data policy.
This step involves the following participants:
CIO
Infrastructure manager
IT managers
Service desk manager
Outcomes of this step
Data retention policy statements for event management
Know the difference between logs and metrics
|
Logs |
Metrics |
||
|---|---|---|---|
|
A log is a complete record of events from a period:
|
Missing entries in logs can be just as telling as the values existing in other entries. | A metric is a numeric value that gives information about a system, generally over a time series. | Adjusting the time series allows different views of the data. |
|
Logs are generally internal constructs to a system:
|
Completeness and context make logs excellent for:
|
As a time series, metrics operate predictably and consistently regardless of system activity. |
This independence makes them ideal for:
|
|
Large amounts of log data can make it difficult to:
|
Context insensitivity means we can apply the same metric to dissimilar systems:
|
||
Understand your data requirements
Amount of event data logged by a 1000 user enterprise averages 113GB/day
Source: SolarWinds
| Security | Logs may contain sensitive information. Best practice is to ensure logs are secure at rest and in transit. Tailor your security protocol to your compliance regulations (PCI, etc.). |
|---|---|
| Architecture and Availability | When production infrastructure goes down, logging tends to go down as well. Holes in your data stream make it much more difficult to determine root causes of incidents. An independent secondary architecture helps solve problems when your primary is offline. At the very least, system agents should be able to buffer data until the pipeline is back online. |
| Performance | Log data grows: organically with the rest of the enterprise and geometrically in the event of a major incident. Your infrastructure design needs to support peak loads to prevent it from being overwhelmed when you need it the most. |
| Access Control | Events have value for multiple process owners in your enterprise. You need to enable access but also ensure data consistency as each group performs their own analysis on the data. |
| Retention | Near-real time data is valuable operationally; historic data is valuable strategically. Find a balance between the two, keeping in mind your obligations under compliance frameworks (GDPR, etc.). |
3.1.1 Set your data policy for every event
- Given your event list in the Event Management Catalog, include the following information for each event:
- Retention Period
- Data Sensitivity
- Data Rate
- Record the results in the Event Management Catalog.
Public Website Example
| Metrics/Log | Retention Period | Data Sensitivity | Data Rate |
|---|---|---|---|
| Latency | 150ms | No | |
| Packet Loss | 10% | No | |
| Jitter | >1ms | No | |
| Response Time | 750ms | No | |
| HAProxy Log | 7 days | Yes | 3GB/day |
| DOM Load time | 1100ms | ||
| Page Load time | 1200ms | ||
| User Access | 3 years | Yes |
Download the Event Management Catalog
Input
- List of events generated by event management
- List of compliance standards your organization adheres to
Output
- Data policy for every event monitored and actioned
Materials
- Whiteboard/flip charts
- Pens
- Paper
Participants
- Event management team
- Infrastructure team
Step 3.2
Set Your Future of Event Monitoring
Activities
3.2.1 Build your roadmap
Start Monitoring and Implement Event Management
This step will walk you through the following activities:
Event management maturity is slowly built over time. Define your future actions in a roadmap to stay on track.
This step involves the following participants:
CIO
Infrastructure manager
IT managers
Outcomes of this step
Event management roadmap and action items
Practice makes perfect
For every event that generates an alert, you want to judge the predictive power of said event.
Engineer your event management practice to be predictive. For example:
- Up/Down Alert – Expected Consequence: Service desk will start working on the incident ticket before a user reports that said system has gone down.
- SysVol Capacity Alert – Expected Consequence: Change will be made to free up space on the volume prior to the system crashing.
If the expected consequence is not observed there are three places to look:
- Was the alert received by the right person?
- Was the alert received in enough time to do something?
- Did the event triggering the alert have a causative relationship with the consequence?
While impractical to look at every action resulting from an alert, a regular review process will help improve your process. Effective alerts are crafted with specific and measurable outcomes.
Info-Tech Insight
False positives are worse than missed positives as they undermine confidence in the entire process from stakeholders and operators. If you need a starting point, action your false positives first.
Mind Your Event Management Errors

Source: IEEE Communications Magazine March 2012
Follow the Cookbook for every event you start tracking
Consider building event management into new, onboarded systems as well.
You now have several core systems, their CIs, conditions, and their related events listed in the Event Catalog. Keep the Catalog as your single reference point to help manage your tracked events across multiple tools.
The Event Management Cookbook is designed to be used over and over. Keep your tracked events standard by running through the steps in the Cookbook.
An additional step you could take is to pull the Cookbook out for event tracking for each new system added to your IT environment. Adding events in the Catalog during application onboarding is a good way to manage and measure configuration.
Event Management Cookbook

Use the framework in the Event Management Cookbook to populate your event catalog with properly tracked and actioned events.
3.2.1 Build an event management roadmap
Increase your event management maturity over time by documenting your goals.
Add the following in-scope goals for future improvement. Include owner, timeline, progress, and priority.
- Add additional systems/applications/services to event management
- Expand condition lists for given systems
- Consolidate tracking tools for easier data analysis and actioning
- Integrate event management with additional service management practices
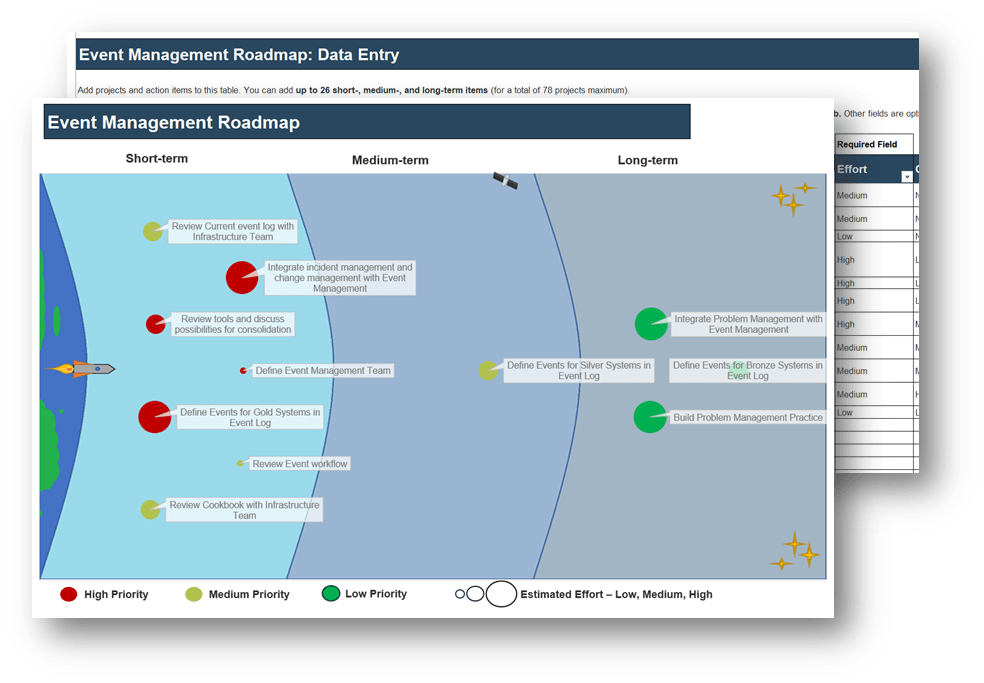
Summary of Accomplishment
Problem Solved
You now have a structured event management process with a start on a properly tracked and actioned event catalog. This will help you detect incidents before they become incidents, changes needed to the IT environment, and problems before they spread.
Continue to use the Event Management Cookbook to add new monitored events to your Event Catalog. This ensures future events will be held to the same or better standard, which allows you to avoid drowning in too much data.
Lastly, stay on track and continually mature your event management practice using your Event Management Roadmap.
If you would like additional support, have our analysts guide you through other phases as part of an Info-Tech workshop
Contact your account representative for more information
workshops@infotech.com
1-888-670-8889
Additional Support
If you would like additional support, have our analysts guide you through other phases as part of an Info-Tech Workshop.
To accelerate this project, engage your IT team in an Info-Tech workshop with an Info-Tech analyst team.
Info-Tech analysts will join you and your team at your location or welcome you to Info-Tech’s historic Toronto office to participate in an innovative onsite workshop.
Contact your account representative for more information.
workshops@infotech.com 1-888-670-8889
The following are sample activities that will be conducted by Info-Tech analysts with your team:
Build a RACI Chart for Event Management
Define and document the roles and responsibilities in event management.
Set Your Scope Using Business Impact
Define and prioritize in-scope systems and services for event management.
Related Info-Tech Research
Standardize the Service Desk
Improve customer service by driving consistency in your support approach and meeting SLAs.
Improve Incident and Problem Management
Don’t let persistent problems govern your department
Harness Configuration Management Superpowers
Build a service configuration management practice around the IT services that are most important to the organization.
Select Bibliography
DeMattia, Adam. “Assessing the Financial Impact of HPE InfoSight Predictive Analytics.” ESG, Softchoice, Sept. 2017. Web.
Hale, Brad. “Estimating Log Generation for Security Information Event and Log Management.” SolarWinds, n.d. Web.
Ho, Cheng-Yuan, et al. “Statistical Analysis of False Positives and False Negatives from Real Traffic with Intrusion Detection/Prevention Systems.” IEEE Communications Magazine, vol. 50, no. 3, 2012, pp. 146-154.
ITIL Foundation ITIL 4 Edition = ITIL 4. The Stationery Office, 2019.
McGillicuddy, Shamus. “EMA: Network Management Megatrends 2016.” Riverbed, April 2016. Web.
McGillicuddy, Shamus. “Network Management Megatrends 2020.” Enterprise Management Associates, APCON, 2020. Web.
Rivas, Genesis. “Event Management: Everything You Need to Know about This ITIL Process.” GB Advisors, 22 Feb. 2021. Web.
“Service Operations Processes.” ITIL Version 3 Chapters, 21 May 2010. Web.