
You have made significant investments in availability and disaster recovery – but your ability to recover hasn’t been tested in years. Testing will:
- Improve your DR capabilities.
- Identify required changes to planning documentation and procedures.
- Validate DR capabilities for interested customers and auditors.
Our Advice
Critical Insight
- If you treat testing as a pass/fail exercise, you aren’t meeting the end goal of improving organizational resilience.
- Focus on identifying gaps and risks, and addressing them, before a real disaster hits.
- Take a realistic, iterative approach to resilience testing that starts with small, low-risk tests and builds on lessons learned.
Impact and Result
- Identify testing scenarios and scope that can deliver value to your organization.
- Create practical test plans with Info-Tech’s template.
- Demonstrate value from testing to gain buy-in for additional tests.
Take a Realistic Approach to Disaster Recovery Testing Research & Tools
Besides the small introduction, subscribers and consulting clients within this management domain have access to:
1. Take a Realistic Approach to Disaster Recovery Testing Storyboard – A guide to establishing a right-sized approach to DR testing that delivers durable value to your organization.
Use this research to understand the different types of tests, prioritize and plan tests for your organization, review the results, and establish a cadence for testing.
- Take a Realistic Approach to Disaster Recovery Testing Storyboard
2. Disaster Recovery Test Plan Template – A template to document your organization's DR test plan.
Use this template to document scope and goals, participants, key pre-test milestones, the test-day schedule, and your findings from the testing exercise.
- Disaster Recovery Test Plan Template
3. Disaster Recovery Testing Program Summary – A template to outline your organization's DR testing program.
Identify the tests you will run over the next year and the expertise, governance, process, and funding required to support testing.
- Disaster Recovery Testing Program Summary
[infographic]
Further reading
Take a Realistic Approach to Disaster Recovery Testing
Reduce costly downtime with a right-sized testing program that improves IT resilience.
Analyst Perspective
Reduce costly downtime with a right-sized testing program that improves IT resilience.

Most businesses make significant investments in disaster recovery and technology resilience. Redundant sites and systems, monitoring, intrusion prevention, backups, training, documentation: it all costs time and money.
But does this investment deliver expected value? Specifically, can you deliver service continuity in a way that meets business requirements?
You can’t know the answer without regularly testing recovery processes and systems. And more than just validation, testing helps you deliver service continuity by finding and addressing gaps in your plans and training your staff on recovery procedures.
Use the insights, tools, and templates in this research to create a streamlined and effective resilience testing program that helps validate recovery capabilities and enhance service reliability, availability, and continuity.
Andrew Sharp
Research Director, Infrastructure & Operations
Info-Tech Research Group
Executive Summary
Your ChallengeYou have made significant investments in availability and disaster recovery (DR) – but your ability to recover hasn’t been tested in years. Testing will:
|
Common ObstaclesDespite the value testing can offer, actually executing on DR tests is difficult because:
|
Info-Tech's ApproachTake a realistic approach to resilience testing by starting with small, low-risk tests, then iterating with the lessons you’ve learned:
|
Info-Tech Insight
If you treat testing as a pass/fail exercise, you aren’t meeting the end goal of improving organizational resilience. Focus on identifying gaps and risks so you can address them before a real disaster hits.
Process and Outputs
This research is accompanied by templates to help you achieve your goals faster.
1 - Establish the business rationale for DR testing.
2 - Review a range of options for testing.
3 - Prioritize tests that are most valuable to your business.
4 - Create a disaster recovery test plan.
5 - Establish a Test Program to support a regular testing cycle.
Outputs:
DR Test PlanDR Testing Program Summary

Orange activity slides like the one on the left provide directions to help you make key decisions.
Key Deliverable:
Disaster Recovery Test Plan Template
Build a plan for your first disaster recovery test.
This document provides a complete example you can use to quickly build your own plan, including goals, milestones, participants, the test-day schedule, and findings from the after-action review.
Why test?
Testing helps you avoid costly downtime
- In a disaster scenario, speed matters. Immediately after an outage, the impact on the organization is small, but impact increases rapidly the longer the outage continues.
- A quick and reliable response and recovery can protect the organization from significant losses.
- A DRP testing and maintenance program helps ensure you’re ready to recover when you need to, rather than figuring it out as you go.
“Routine testing is vital to survive a disaster… that’s when muscle memory sets in. If you don’t test your DR plan it falls [in importance], and you never see how routine changes impact it.”
– Jennifer Goshorn
Chief Administrative Officer
Gunderson Dettmer LLP
Info-Tech members estimated even one day of system downtime could lead to significant revenue losses. 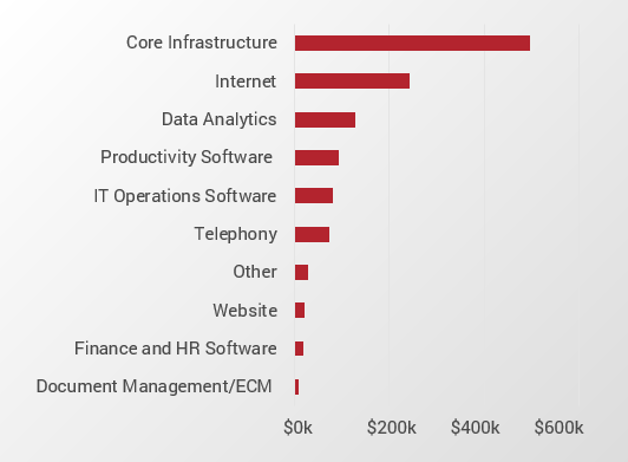
Average estimated potential loss* in thousands of USD due to a 24-hour outage (N=41)
*Data aggregated from 41 business impact analyses (BIAs) conducted with Info-Tech advisory assistance. BIAs evaluate potential revenue loss due to a full day of system downtime, at the worst possible time.
Run tests to enhance disaster recovery plans
Testing improves organizational resilience
- Identify and address gaps in your plans before a real disaster strikes.
- Cross-train staff on systems recovery.
- Go beyond testing technology to test recovery processes.
- Establish a culture that centers resilience in everyday decision-making.
Testing keeps DR documentation ready for action
- Update documentation ahead of tests to prepare for the testing exercise.
- Update documentation after testing to incorporate any lessons learned.
Testing validates that investments in resilience deliver value
- Confirm your organization can meet defined recovery time objectives (RTOs) and recovery point objectives (RPOs).
- Provide proof of testing for auditors, prospective customers, and insurance applications
Overcome testing challenges
Despite the value of effective recovery testing, most IT organizations struggle to test recovery plans
Common challenges
- Key resources don’t have time for testing exercises.
- You don’t have the technology to support live recovery testing.
- Tests are done ad hoc and lessons learned are lost.
- A lack of business support for test exercises as the value isn’t understood.
- Tests are always artificially simple because RTOs and RPOs must be met to satisfy customer or auditor inquiries
Overcome challenges with a realistic approach:
- Start small with tabletop and recovery tests for specific systems.
- Include recovery tests in operational tasks (e.g. restore systems when you have a maintenance window).
- Create testing plans for larger testing exercises.
- Build on successful tests to streamline testing exercises in the future.
- Don’t make testing a pass-fail exercise. Focus on identifying gaps and risks so you can address them before a real disaster hits.
Go beyond traditional testing
Different test techniques help validate recovery against different threats
- There are many threats to service continuity, including ransomware, severe weather events, geopolitical conflict, legacy systems, staff turnover, and day-to-day outages caused by human error, software updates, hardware failures, or network outages.
- At its core, disaster recovery planning is about recovery. A plan for service recovery will help you mitigate against many threats at once. The testing approaches on the right will help you validate different aspects of that recovery process.
- This research will provide an overview of the approaches outlined on the right and help you prioritize tests that are most valuable to your organization.

00 Identify a working group
30 minutes
Identify a group of participants who can fill the following roles and inform the discussions around testing in this research. A single person could fill multiple roles and some roles could be filled by multiple people. Many participants will be drawn from the larger DRP team.

Input
|
Output
|
Participants
|
Start by updating your disaster recovery plan (DRP)
Use Info-Tech’s Create a Right-Sized Disaster Recovery Plan research to identify recovery objectives based on business impact and outline recovery processes. Both are tremendously valuable inputs to your test plans.
Overall Business Continuity Plan
IT Disaster Recovery PlanA plan to restore IT services (e.g. applications and infrastructure) following a disruption. A DRP:
|
BCP for Each Business UnitA set of plans to resume business processes for each business unit. A business continuity plan (BCP) is also sometimes called a continuity of operations plan (COOP). BCPs are created and owned by each business unit, and creating a BCP requires deep involvement from the leadership of each business unit. Info-Tech’s Develop a Business Continuity Plan blueprint provides a methodology for creating business unit BCPs as part of an overall BCP for the organization. |
Crisis Management PlanA plan to manage a wide range of crises, from health and safety incidents to business disruptions to reputational damage. Info-Tech’s Implement Crisis Management Best Practices blueprint provides a framework for planning a response to any crisis, from health and safety incidents to reputational damage. |
01 Confirm: why test at all?
15-30 minutes
Identify the value recovery testing for your organization. Use language appropriate for a nontechnical audience. Start with the list below and add, modify, or delete bullet points to reflect your own organization.
Drivers for testing – Examples:
- Improve service continuity.
- Identify and address gaps in recovery plans before a real disaster strikes.
- Cross-train staff on systems recovery to minimize single points of failure.
- Identify how we coordinate across teams during a major systems outage.
- Exercise both recovery processes and technology.
- Support a culture that centers system resilience in everyday decision-making.
- Keep recovery documentation up-to-date and ready for action.
- Confirm that our stated recovery objectives can be met.
- Provide proof of testing for auditors, prospective customers, and insurance applications.
- We require proof of testing to pass audits and renew cybersecurity insurance.
Info-Tech Insight
Time-strapped technical staff will sometimes push back on planning and testing, objecting that the team will “figure it out” in a disaster. But the question isn’t whether recovery is possible – it’s whether the recovery aligns with business needs. If your plan is to “MacGyver” a solution on the fly, you can’t know if it’s the right solution for your organization.
Input
|
Output
|
Participants
|
Think about what and how you test
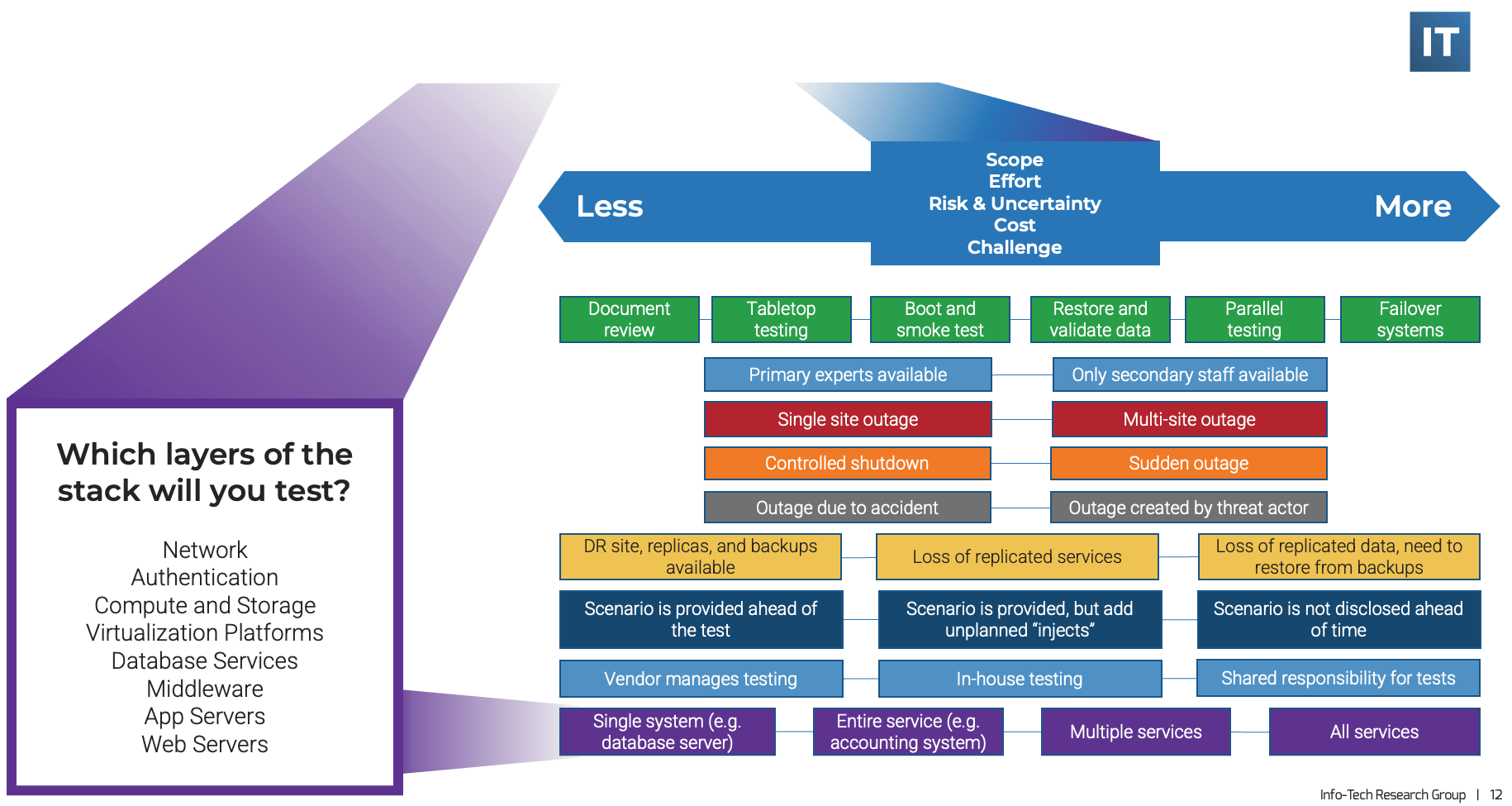
Find gaps and risks with tabletop testing
In a tabletop planning exercise, the team walks through a disaster scenario to outline the recovery workflow, and risks or gaps that could disrupt that workflow.
Tabletops are particularly effective because:
- It enables you to play out a wider range of scenarios than technology-based testing (e.g. full-scale, parallel) due to cost and complexity factors.
- It is non-intrusive, so it can be executed more easily than other testing methodologies.
- The exercise translates into recovery documentation: you create a workflow as you go.
- A major site or service recovery scenario will review all aspects of the recovery process and create the backbone of your recovery plan.
02 Run a tabletop exercise
2 hours
Tabletop testing is part of our core DRP methodology, Create a Right-Sized Disaster Recovery Plan. This exercise can be run using cue cards, sticky notes, or on a whiteboard; many of our facilitators find building the workflow directly in flowchart software to be very effective.
Use our Recovery Workflow Template as a starting point.
Some tips for running your first tabletop exercise:
Do
|
Don't
|
- Ahead of the exercise, decide on a scenario, identify participants, and book a meeting time.
- For your first walkthrough of a DR scenario, we often recommend a scenario that considers a site failure requiring failover to a DR site.
- For the first exercise, focus on technical aspects of recovery before bringing in members of the business. The technical team may need space to discuss the appropriate steps in the recovery process before you bring in business liaisons to discuss user acceptance testing (UAT).
- A complete failover considers all systems, the viability of your second site, and can help identify parts of the process that require additional exercises.
- Review the scenario with participants. Then, discuss and document the recovery process, starting with initial notification of an event.
- Record steps in the process on white cards or boxes.
- On yellow and red cards, document gaps and risks in people process and technology requirements.
- Once you’ve walked through the process, return to the start.
- Record the time required to complete each step. Consider identifying who is responsible for key steps. Identify any additional gaps and risks.
- Clean up and record the results of the workflow. Save a copy with your DRP documentation.
Input
|
Output
|
Participants
|
Move from tabletop testing to functional exercises
See how your plans fare in the real world
In live exercises, some portion of your recovery plans are executed in a way that mimics a real recovery scenario. Some advantages of live testing:
- See how standby systems behave. A tabletop exercise can miss small issues that can make or break the recovery process. For example, connectivity or integration issues on a new subnet might be difficult to predict prior to actually running services in that environment.
- Hands-on practice: Familiarize the team with the steps, commands, and interfaces of your recovery toolset.
- Manage the pressure of the DR scenario: Nothing’s quite like the real thing, but a live exercise may be the closest your team can get to a disaster situation without experiencing it firsthand.
Examples of live exercises
| Boot and smoke test | Turn on a standby system and confirm it boots up correctly. |
| Restore and validate data | Restore data or servers from backup. Confirm data integrity. |
| Parallel testing | Send familiar transactions to production and standby systems. Confirm both systems produce the same result. |
| Failover systems | Shut down the production system and use the standby system in production. |
Run local tests ahead of releases
Think small
Most unacceptable downtime is caused by localized issues, such as hardware or software failures, rather than widespread destructive events. Regular local testing can help validate the recovery plan for local issues and improve overall service continuity.
Make local testing a standard step in maintenance work and new deployments to embed resilience considerations in day-to-day activities. Run the same tests in both your primary and your DR environment.
Some examples of localized tests:
- Review backup logs and check for errors.
- Restore files or whole systems from backup.
- Run application-based tests as part of release management, including unit, regression, and performance tests.
- Ensure application tests are run for both the primary and DR environment.
- For a deep-dive on application testing, see Info-Tech’s research Automate Testing to Get More Done.
Info-Tech Insight
Local tests will vary between different services, and local test design is usually best left to the system SMEs. At the same time, centralize reporting to understand where tests are being done.
Investigate whether your IT Service Management or ticketing system can create recurring tasks or work orders to schedule, document, and track test exercises. Tasks can be pre-populated with checklists and documentation to support the test and provide a record of completed tests to support oversight and reporting.
Have the business validate recovery
If your business doesn’t think a system’s recovered, it’s not recovered.
User acceptance testing (UAT) after system recovery is a key step in the recovery process. Like any step in the process, there’s value in testing it before it actually needs to be done. Assign responsibility for building UATs to the person who will be responsible for executing them.
An acceptance test script might look something like the checklist below.
- Does the application open?
- Does the interface look right?
- Do you see any unusual notifications or warnings?
- Can you conduct a key transaction with dummy data?
- Can you run key reports?
“I cannot stress how important it is to assign ownership of responsibilities in a test; this is the only way to truly mitigate against issues in a test.”
– Robert Nardella
IT Service Management
Certified z/OS Mainframe Professional
Info-Tech Insight
Build test scripts and test transactions ahead of time to minimize the amount of new work required during a recovery scenario.
Beyond the Basics: Full Failover Testing
- A failover test – a full failover of your production environment to a secondary environment – is what many IT and businesspeople think about when they think of disaster recovery testing.
- A full test can validate previous local or tabletop tests, identify additional gaps and risks, and provide hands-on training experience with recovery processes and technologies.
- Setting a date for failover testing can also inject some urgency into otherwise low-priority (but high importance) disaster recovery planning and documentation exercises, which need to be completed prior to the test.
- Despite these benefits, full failover tests carry significant risk and require a great deal of effort and cost. Typically, only businesses that already have an active-active environment capable of supporting in-scope production systems are able to run a full environment failover.
- This is especially true the first time you test. While in theory a DR plan should be ready to go at any time, there will be documents to update, gaps to address, and risks to mitigate before you go ahead with the test.
Full Failover Testing
What you get:
- Provide hands-on experience with recovery processes and technology.
- Confirm that site failover works in practice as you assumed in tabletop or local testing exercises.
- Identify critical gaps you might have missed without a full failover test.
What you need:
- An active-active secondary site, with sufficient standby equipment, data, and licensed standby software to support production.
- A completed tabletop exercise and documented recovery workflow.
- A documented test plan, backout plan, and formal sign-off.
- An off-hours downtime window.
- Time from technical SMEs and business resources, both for creating the plan and executing the test.
Beyond the Basics: Site Reliability Engineering
- Site reliability engineering (SRE) is an application of skills and approaches from software engineering to improve system resilience.
- SRE is focused on “availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning” across a set portfolio of services (Sloss, 2017).
- In many organizations, SRE is implemented as a team that supports separate applications teams.
- Applications must have defined and granular resilience requirements, translated into service objectives. The SRE team and applications teams will work together to meet these objectives.
- Site reliability engineers (the folks that do SRE, and often also abbreviated as SREs) are expected to build solutions and processes to ensure services remain stable and performant, not just respond when they fail. For example, Google allows their SREs to spend just half their time on incident response, with the rest of their time focused on development and automation tasks.
Site Reliability Testing
What you get:
- Improved reliability and reduced frequency and impact of downtime.
- Increased use of automation to address problems before they cause an incident.
- Granular resilience objectives.
What you need:
- Systems running on software-defined infrastructure.
- Specialized skills in programming, infrastructure-as-code.
- Business & product owners able to define and fund acceptable and appropriate resilience objectives.
- Technical experts able to translate product requirements into technical design requirements.
Beyond the Basics: Chaos Engineering
- Chaos engineering, a term and approach first popularized by the team at Netflix, aims to improve the resilience of particularly large and distributed systems by simulating system failures and evaluating performance against a baseline.
- Experiments simulate a variety of real-world events that could cause outages (e.g. network slowdowns or server failures). Experiments run continuously, and the recommendation is to run them in production where feasible while minimizing the impact on customers.
- Tools to help you run chaos testing exist, including open-source toolkits like Chaos Monkey or Mangle and paid software as a service (SaaS) solutions like Gremlin.
- Deciding whether the long-term benefits of tests that can degrade production are worth the potential risk of system slowdowns or outages is a business or product decision. Technical considerations aside, if the business owner of a particular system doesn’t see the value of continuous testing outweighing the introduced risk, this approach to testing isn’t going to happen.
Chaos Engineering
What you get:
- Confidence that systems can weather volatile and unpredictable conditions in a production environment.
- An embedded resilience culture.
What you need:
- High-maturity IT incident, monitoring and event practices.
- Standby/resilient systems to minimize downtime impact.
- Business buy-in for introducing risk into the production environment.
- Specialized skills to identify, develop, and run tests that degrade production performance in a controlled way.
- Budget and time to act on issues identified through testing.
Beyond the Basics: Security Event Simulations
- Ransomware is driving demands for proof of recovery testing from customers, executives, auditors, and insurance companies. Systems recovery is part of ransomware recovery, but recovering from a breach includes detection, analysis, containment, and eradication of the attack vector before systems recovery can begin.
- Beyond technical recovery, internal legal and communications teams will have a role, as will your insurance provider, consultants specialized in ransomware recovery, or professional ransom negotiators.
- A tabletop exercise focused on ransomware incident response is a key first step. You can find Info-Tech’s methodology for a ransomware tabletop in Phase 3 of Build Resilience Against Ransomware Attacks.
- Live testing approaches can offer hands-on experience and further insight into how your systems are vulnerable to malware. A variety of open source and proprietary tools can simulate ransomware and help you identify problems, though it’s important to understand the limitations of different simulators (Allon, 2022).
- A “red team” exercise simulates an adversarial attack against your processes and systems. A specialized penetration tester will often take on the role of the red team and provide a report of identified gaps and risks after the engagement.
Security Event Simulation
What you get:
- Hands-on experience managing and recovering from a ransomware attack in a controlled environment.
- A better understanding of gaps in your response process.
What you need:
- A completed ransomware tabletop exercise and mature security incident response processes.
- For Ransomware Simulators: An air-gapped sandbox environment hosting a copy of your production systems and security tools, and time from your technical SMEs.
- For Red Team Exercises: A trusted provider, scope for your testing plans, and time from your security incident response team.
Prioritize tests by asking these three questions
1. Will the scope of this test deliver sufficient value?
- Yes, these are critical systems with low tolerance for downtime or data loss.
- Yes, major changes or new systems require validation of DR capabilities.
- Yes, there’s high probability of an outage, or recent experience of an outage.
- •Yes, we have audit requirements or customer demands for testing.
2. Are we ready for this test?
- Yes, recovery plans and recovery objectives are documented.
- Yes, key technical and business resources have time to commit to testing exercises.
- Yes, technology is currently able to support proposed tests.
3. Is it easy to do?
- Yes, effort required to complete the test is low (i.e. minimal work, few participants).
- Yes, the risks related to testing are low.
- Yes, it won’t cost much.
Info-Tech Insight
More complex, challenging, risky, or costly tests, such as full failover tests, can deliver value. But do the high-value, low-effort stuff first!
03 Brainstorm and prioritize test ideas
30-60 minutes
Even if you have an idea of what you need to test and how you want to run those tests, this brainstorming exercise can generate useful ideas for testing that might otherwise have been missed.
- Review the slides above to develop ideas on how and what you want to test. These slides may be enough to kickstart a brainstorming process. Don’t debate or discount ideas at this point. Write down these ideas in a space where all participants can see them (e.g. whiteboard or shared screen).
The next steps will help you prioritize the list – if needed – to tests that are highest value and lowest effort.
- Discuss where you have the greatest need to test. Assign a score of 0 – 3 for each test, with a score of 3 being high-need and a score of zero being low-need. Consider whether:
- These applications have a low tolerance for downtime.
- There’s a high chance of an outage, or recent experience with an outage.
- There’s a need to train or cross-train staff on recovery for the system(s) in question.
- Major changes require a review or validation of DR capabilities.
- Audit requirements or customer/executive demands can be met via testing.
- Discuss which tests will require the least effort to complete – where readiness is high and tests are easier to do. Assign a score between 0 and 3 for each test, with a score of 3 being least effort and a score of 0 being high effort. Consider whether:
- Recovery plans and recovery objectives are documented for these systems.
- Technical experts are available to work on testing exercises.
- For active testing, standby/sandbox systems are available and capable of supporting proposed tests.
- The effort required to complete the test is low (e.g. minimal new work, few participants).
- The risks related to testing are low.
- You will need to secure additional funding.
- Sum together the assigned scores for each test. Higher scores should be the highest priority, but of course use your judgement to validate the results and select one or two tests to execute in the coming year.
“There are different levels of testing and it is very progressive. I do not recommend my clients to do anything, unless they do it in a progressive fashion. Don’t try to do a live failover test with your users, right out of the box.”
– Steve Tower
Principal Consultant
Prompta Consulting Group
Input
|
Output
|
Participants
|
04 Build a test plan
3-5 days
Building a test plan helps the test run smoothly and can uncover issues with the underlying DRP as you dig into the details.
The test coordinator will own the plan document but will rely on the sponsor to confirm scope and goals, technical SMEs to develop system recovery plans, and business liaisons to create UAT scripts.
Download Info-Tech’s Disaster Recovery Test Plan Template. Use the structure of the template to build your own document, deleting example data as you go. Consider saving a separate copy of this document as an example and working from a second copy.
Key sections of the document include:
- Goals, scenario, and scope of the test.
- Assumptions, constraints, risks, and mitigation strategies.
- Test participants.
- Key pre-test milestones, and test-day schedule.
- After-action review.
Download the Disaster Recovery Test Plan Template
Input
|
Output
|
Participants
|
05 Run an after-action review
30-60 minutes
Take time after test exercises – especially large-scale tests with many participants – to consider what went well, what didn’t, and where you can improve future testing exercises. Track lessons learned and next steps at the bottom of your test plan.
- Start with a short (5-10 minute) debrief of the test and allow participants to ask questions. Confirm:
- Did we meet the goals we set for the exercise, including RTOs and RPOs?
- What was done well? What issues, gaps, and risks were identified?
- Work through variations of the following questions:
- Was the test plan effective, and was the test well organized?
- Was the documentation effective? Where did we follow the plan as documented, and where did we deviate from the plan?
- Was our communication/collaboration during the test effective?
- Have gaps and issues found during the test been reported to the testing coordinator? Could some of the issues uncovered apply more broadly to other IT services as well?
- What could we test next, based on what was discovered?
- Are there other tools or approaches that could be useful?
Input
|
Output
|
Participants
|
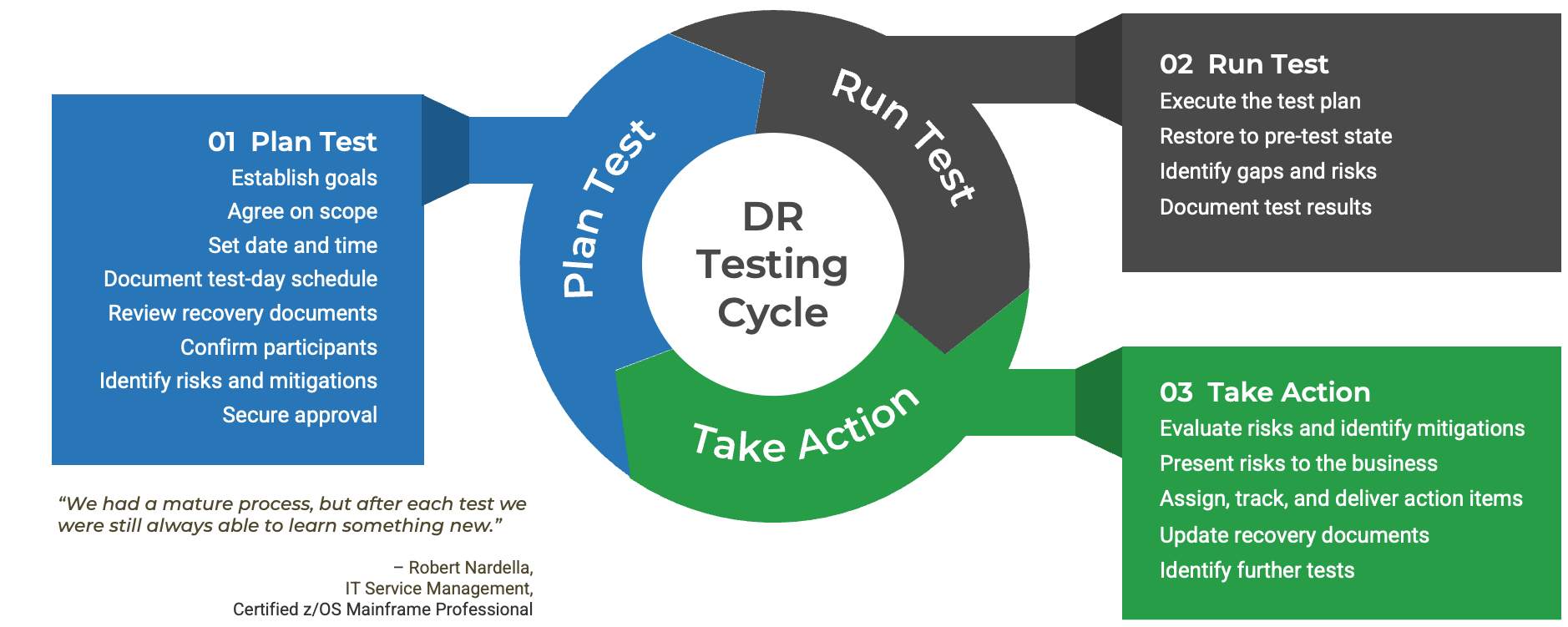
Follow a testing cycle
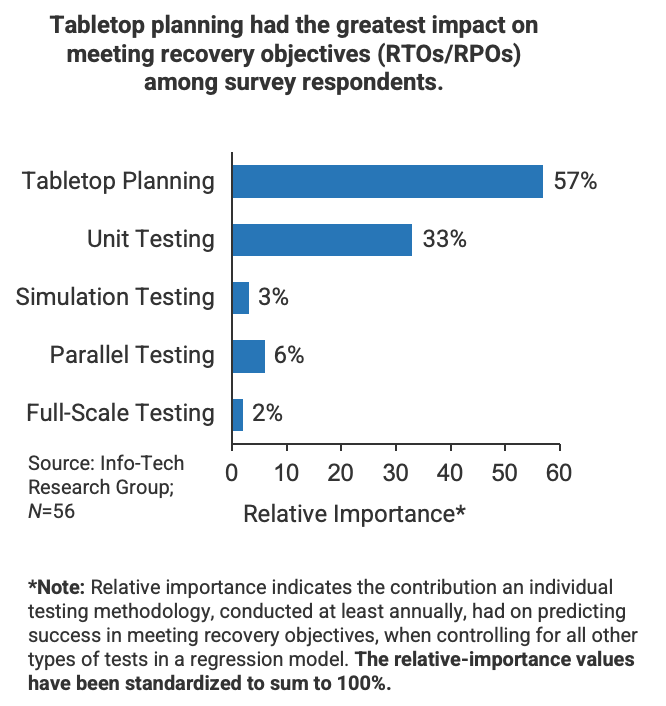
All tests are expected to drive actions to improve resilience, as appropriate. Experience from previous tests will be applied to future testing exercises.
Use your experience to simplify testing
The fifth testing exercise should be easier than the first
Outputs and lessons learned from testing should help you run future tests.
- With past experience under their belt, participants should have a better understanding of their role, and of their peers’ roles, and the goal of the exercise.
- Facilitators will be more comfortable facilitating the exercise, and everyone should be more confident in the steps required to recover their systems.
- Gather feedback from participants through after-action reviews to identify what worked and what didn’t.
- Documentation from previous tests can provide a template for future tests.
- Gaps identified in previous tests can provide ideas for future tests.

Info-Tech Insight
Testing should get easier over time. But if you’re easily passing every test, it’s a sign that you’re ready to run more challenging tests.
06 Create a test program summary
2-4 hours
Regular testing allows you to build on prior tests and helps keep plans current despite changes to your environment.
Keeping a regular testing schedule requires expertise, a process to coordinate your efforts, and a level of governance to provide oversight and ensure testing continues to deliver value. Create a call to action using Info-Tech’s Disaster Recovery Testing Program Summary Template.
The result is a summary document that:
- Identifies key takeaways and testing goals
- Presents key elements of the testing program
- Outlines the testing cycle
- Lists expected milestones for the next year
- Identifies participants
- Recommends next steps
“It is extremely important in the early stages of development to concentrate the focus on actual recoverability and data protection, enhancing these capabilities over time into a fully matured program that can truly test the recovery, and not simply focusing on the testing process itself.”
– Joe Starzyk
Senior Business Development Executive
IBM Global Services
Research Contributors and Experts
- Bernard A. Jones, Business Continuity & Disaster Recovery Expert
- Robert Nardella, IT Service Management, Certified z/OS Mainframe Professional
- Larry Liss, Chief Technology Officer, Blank Rome LLP
- Jennifer Goshorn, Chief Administrative and Chief Compliance Officer, Gunderson Dettmer LLP
- Paul Kirvan, FBCI, CISA, Independent IT Consultant/Auditor, Paul Kirvan Associates
- Steve Tower, Principal Consultant, Prompta Consulting Group
- Joe Starzyk, Senior Business Development Executive, IBM Global Services
- Thomas Bronack, Enterprise Resiliency and Corporate Certification Consultant, DCAG
- Paul S. Randal, CEO & Owner, SQLskills.com
- Tom Baumgartner, Disaster Recovery Analyst, Catholic Health
Bibliography
Alton, Yoni. “Ransomware simulators – reality or a bluff?” Palo Alto Blog, 2 May 2022. Accessed 31 Jan 2023.
https://www.paloaltonetworks.com/blog/security-operations/ransomware-simulators-reality-or-a-bluff/
Brathwaite, Shimon. “How to Test your Business Continuity and Disaster Recovery Plan,” Security Made Simple, 13 Nov 2022. Accessed 31 Jan 2023.
https://www.securitymadesimple.org/cybersecurity-blog/how-to-test-your-business-continuity-and-disaster-recovery-plan
The Business Continuity Institute. Good Practice Guidelines: 2018 Edition. The Business Continuity Institute, 2017.
Emigh, Jacqueline. “Disaster Recovery Testing: Ensuring Your DR Plan Works,” Enterprise Storage Forum, 28 May 2019. Accessed 31 Jan 2023.
Disaster Recovery Testing: Ensuring Your DR Plan Works | Enterprise Storage Forum
Gardner, Dana. "Case Study: Strategic Approach to Disaster Recovery and Data Lifecycle Management Pays off for Australia's SAI Global." ZDNet. BriefingsDirect, 26 Apr 2012. Accessed 31 Jan 2023.
http://www.zdnet.com/article/case-study-strategic-approach-to-disaster-recovery-and-data-lifecycle-management-pays-off-for-australias-sai-global/.
IBM. “Section 11. Testing the Disaster Recovery Plan.” IBM, 2 Aug 2021. Accessed 31 Jan 2023. Section 11. Testing the disaster recovery plan - IBM Documentation Lutkevich, Ben and Alexander Gillis. “Chaos Engineering”. TechTarget, Jun 2021. Accessed 31 Jan 2023.
https://www.techtarget.com/searchitoperations/definition/chaos-engineering
Monperrus, Martin. “Principles of Antifragility.” Arxiv Forum, 7 June 2017. Accessed 31 Jan 2023.
https://arxiv.org/ftp/arxiv/papers/1404/1404.3056.pdf
“Principles of Chaos Engineering.” Principles of Chaos Engineering, 2019 March. Accessed 31 Jan 2023.
https://principlesofchaos.org/
Sloss, Benjamin Treynor. “Introduction.” Site Reliability Engineering. Ed. Betsy Beyer. O’Reilly Media, 2017. Accessed 31 Jan 2023.
https://sre.google/sre-book/introduction/