
- Senior leadership is asking difficult questions about the organization’s dependency on third-party cloud services and the risk that poses.
- IT leaders have limited control over third-party incidents and that includes cloud services. Yet they are on the hot seat when cloud services go down.
- While vendors have swooped in to provide resilience options for the more-common SaaS solutions, it is not the case for all cloud services.
Our Advice
Critical Insight
- No control over the software does not mean no recovery options. Solutions range from designing an IT workaround using alternate technologies to pre-defined third-party service continuity options (e.g. see options for O365) to business workarounds.
- Even where there is limited control, you can at least define an incident response plan to streamline notification, assessment, and implementation of workarounds. Leadership wants more options than simply waiting for the service to come back online.
- At a minimum, IT’s responsibility is to identify and communicate risk to senior leadership. That starts with a vendor review to identify SLA issues and overall resilience gaps.
Impact and Result
- Follow a structured process to assess cloud resilience risk.
- Identify opportunities to mitigate risk – at the very least, ensure critical data is protected.
- Summarize cloud services risk, mitigation options, and incident response for senior leadership.
Mitigate the Risk of Cloud Downtime and Data Loss Research & Tools
Besides the small introduction, subscribers and consulting clients within this management domain have access to:
1. Mitigate the Risk of Cloud Downtime and Data Loss – Step-by-step guide to assess risk, identify risk mitigation options, and create an incident response plan.
Even where there is limited control, you can define an incident response plan to streamline notification, assessment, and implementation of workarounds.
- Mitigate the Risk of Cloud Downtime and Data Loss Storyboard
2. Cloud Services Incident Risk and Mitigation Review – Review your key cloud vendors’ SLAs, incident preparedness, and data protection strategy.
At a minimum, IT’s responsibility is to identify and communicate risk to senior leadership. That starts with a vendor review to identify SLA and overall resilience gaps.
- Cloud Services Incident Risk and Mitigation Review Tool
3. SaaS Incident Response Workflows – Use these examples to guide your efforts to create cloud incident response workflows.
The examples illustrate different approaches to incident response depending on the criticality of the service and options available.
- SaaS Incident Response Workflows (Visio)
- SaaS Incident Response Workflows (PDF)
4. Cloud Services Resilience Summary – Use this template to capture your results.
Summarize cloud services risk, mitigation options, and incident response for senior leadership.
- Cloud Services Resilience Summary
Further reading
Mitigate the Risk of Cloud Downtime and Data Loss
Resilience and disaster recovery in an increasingly Cloudy and SaaSy world.
Analyst Perspective
If you think cloud means you don’t need a response plan, then get your resume ready.
|
Most organizations are now recognizing that they can’t ignore the risk of a cloud outage or data loss, and the challenge is “what can I do about it?” since there is limited control. If you still think “it’s in the cloud, so I don’t need to worry about it,” then get your resume ready. When O365 goes down, your executives are calling IT, not Microsoft, for an answer of what’s being done and what can they do in the meantime to get the business up and running again. The key is to recognize what you can control and what actions you can take to evaluate and mitigate risk. At a minimum, you can ensure senior leadership is aware of the risk and define a plan for how you will respond to an incident, even if that is limited to monitoring and communicating status. Often you can do more, including defining IT workarounds, backing up your SaaS data for additional protection, and using business process workarounds to bridge the gap, as illustrated in the case studies in this blueprint. Frank Trovato Info-Tech Research Group |

Use this blueprint to expand your DRP and BCP to account for cloud services
As more applications are migrated to cloud-based services, disaster recovery (DR) and business continuity plans (BCP) must include an understanding of cloud risks and actions to mitigate those risks. This includes evaluating vendor and service reliability and resilience, security measures, data protection capabilities, and technology and business workarounds if there is a cloud outage or incident.
Use the risk assessments and cloud service incident response plans developed through this blueprint to supplement your DRP and BCP as well as further inform your crisis management plans (e.g. account for cloud risks in your crisis communication planning).
Overall Business Continuity Plan |
||
|---|---|---|
IT Disaster Recovery Plan A plan to restore IT application and infrastructure services following a disruption. Info-Tech’s Disaster Recovery Planning blueprint provides a methodology for creating the IT DRP. Leverage this blueprint to validate and provide inputs for your IT DRP. |
BCP for Each Business Unit A set of plans to resume business processes for each business unit. Info-Tech’s Develop a Business Continuity Plan blueprint provides a methodology for creating business unit BCPs as part of an overall BCP for the organization. |
Crisis Management Plan A plan to manage a wide range of crises, from health and safety incidents to business disruptions to reputational damage. Info-Tech’s Implement Crisis Management Best Practices blueprint provides a framework for planning a response to any crisis, from health and safety incidents to reputational damage. |
Executive Summary
Your Challenge |
Common Obstacles |
Info-Tech’s Approach |
|---|---|---|
|
|
|
Info-Tech Insight
Asking vendors about their DRP, BCP, and overall resilience has become commonplace. Expect your vendors to provide answers so you can assess risk. Furthermore, your vendor may have additional offerings to increase resilience or recommendations for third parties who can further assist your goals of improving cloud service resilience.
Key deliverable
Cloud Services Resilience Summary
Provide leadership with a summary of cloud risk, downtime workarounds implemented, and additional data protection.

Additional tools and templates in this blueprint
Cloud Services Incident Risk and Mitigation Review Tool Use this tool to gather vendor input, evaluate vendor SLAs and overall resilience, and track your own risk mitigation efforts.
|
SaaS Incident Response Workflows Use the examples in this document as a model to develop your own incident response workflows for cloud outages or data loss.
|
This blueprint will step you through the following actions to evaluate and mitigate cloud services risk
- Assess your cloud risk
- Review your cloud services to determine potential impact of downtime/data loss, vendor SLA gaps, and vendor’s current resilience.
- Explore your cloud vendor’s resilience offerings, third-party solutions, DIY recovery options, and business workarounds.
- Document your cloud risk mitigation strategy and incident response plan, which might include a failover strategy, data protection, and/or business continuity.
Cloud Risk Mitigation
Identify options to mitigate risk
Create an incident response plan
Assess risk
Phase 1: Assess your cloud risk
Phase 1 | Phase 2 | Phase 3 |
|---|---|---|
Assess your cloud risk | Identify options to mitigate risk | Create an incident response plan |
Cloud does not guarantee uptime
Public cloud services (e.g. Azure, GCP, AWS) and popular SaaS solutions experience downtime every year.
A few cloud outage examples:
- Microsoft Azure AD outage, March 15, 2022:
Many users could not log into O365, Dynamics, or the Azure Portal.
Cause: software change. - Three AWS outages in December 2021: December 7 (Netflix and others impacted), December 15 (Duo, Zoom, Slack, others), December 20 (Slack, Epic Games, others). Cause: network issues, power outage.
- Salesforce outage, May 12, 2022: Users could not access the Lightning platform. Cause: expired certificate.
Cloud availability
- Migrating to cloud services can improve availability, as they typically offer more resilience than most organizations can afford to implement themselves.
- However, having multiple data centers, zones, and regions doesn’t prevent all outages, as we see every year with even the largest cloud vendors.
DR challenges for IaaS, PaaS, and cloud-native
While there are limits to what you control, often traditional “failover” DR strategy can apply.
High-level challenges and resilience options:
- IaaS: No control over the hardware, but you can failover to another region. This is fairly similar to traditional DR.
- PaaS: No control over the software platform (e.g. SQL server as a service), but you can back up your data and explore vendor options to replicate your environment.
- Cloud-native applications: As with PaaS, you can back up your data and explore vendor options to replicate your environment.
Plan for resilience
- Include DR requirements when designing cloud service implementation. For example, for IaaS solutions, identify what data would need to be replicated and what services may need to be “always on” (e.g. database services where high-availability is demanded).
- Similarly, for PaaS and cloud-native solutions, consult your vendor regarding options to build in resilience options (e.g. ability to failover to another environment).
DR challenges for SaaS solutions
SaaS is the biggest challenge because you have no control over any part of the base application stack.
High-level challenges and resilience options:
- No control over the hardware (or the facility, maintenance processes, and so on).
- No control over the base application (control is limited to configuration settings and add-on customizations or integrations).
- Options to back up your data will depend on the service.
Note: The rest of this blueprint is focused primarily on SaaS resilience due to the challenges listed here. For other cloud services, leverage traditional DR strategies and vendor management to mitigate risk (as summarized on the previous slides).
Focus on what you can control
- For SaaS solutions in particular, you must toss out traditional DR. If Salesforce has an outage, you won’t be involved in recovering the system.
- Instead, DR for SaaS needs to focus on improving resilience where you do have control and implementing business workarounds to bridge the gap.
Evaluate your cloud services to clarify your specific risks
Time and money is limited, so focus first on cloud services that are most critical and evaluate the vendors’ SLA and existing resilience capabilities.
The activities on the next two slides will evaluate risk through two approaches:
Activity 1: Estimate potential impact of downtime and data loss to quantify the risk and determine which cloud services are most critical and need to be prioritized. This is done through a business impact analysis that assesses:
|
Activity 2: Review the vendor to identify risks and gaps. Specifically, evaluate the following:
|
Activity 1: Quantify potential impact and prioritize cloud services using a business impact analysis (BIA)
1-3 hours
- Download the latest version of our DRP BIA: DRP Business Impact Analysis Tool. The tool includes instructions.
- Include the cloud services you want to assess in the list of applications/systems (see the tool excerpt below), and follow the BIA methodology outlined in the Create a Right-Sized Disaster Recovery Plan blueprint.
- Use the results to quantify potential impact and prioritize your efforts on the most-critical cloud services.
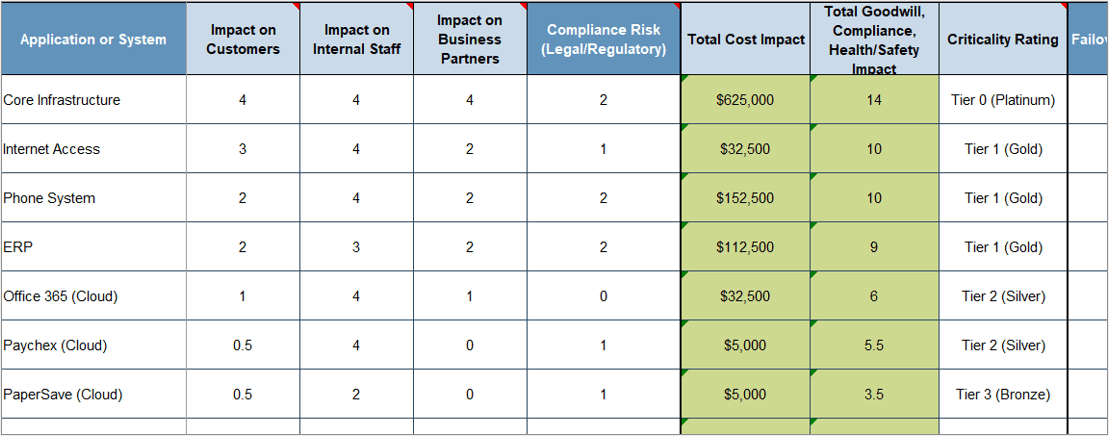
| Materials |
|---|
|
| Participants |
|
Activity 2: Review your key cloud vendors’ SLAs, incident preparedness, and data protection strategy
1-3 hours
Use the Cloud Services Incident Risk and Mitigation Review Tool as follows:
- Send the Vendor Questionnaire tab to your cloud vendors to gather input, and review your existing agreements.
- Copy the vendor responses into the tool (see the instructions in the tool) and evaluate. See the example excerpt below.
- Identify action items to clarify gaps or address risks. Some action items might not be defined yet and will need to wait until you have had a chance to further explore risk mitigation options.
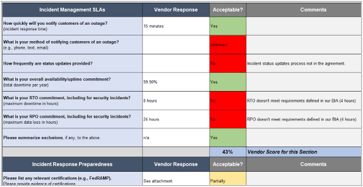
| Materials |
|---|
|
| Participants |
|
Phase 2: Identify options to mitigate risk
Phase 1 | Phase 2 | Phase 3 |
|---|---|---|
Assess your cloud risk | Identify options to mitigate risk | Create an incident response plan |
Consult your vendor to identify options to improve resilience, as a starting point
Your vendor might also be able to suggest third parties that offer additional support, backup, or service continuity options.
- The Vendor Questionnaire tab in the Cloud Services Incident Risk and Mitigation Review Tool includes a section at the bottom where your vendor can name additional options to improve resilience (e.g. premium support packages, potentially their own DR services).
- If your vendor has not completed that part of the questionnaire, meet with them to discuss this. Asking service vendors about resilience has become commonplace, so they should be prepared to answer questions about their own offerings and potentially can name trusted third-party vendors who can further assist you.
- Leverage Info-Tech’s advisory services to evaluate options outlined by your vendor and potential third-party options (e.g. enterprise backup solutions that support backing up SaaS data).
Some SaaS solutions have plenty of resilience options; others not so much
- The pervasiveness of O365 has led vendors to close the service continuity gap, with options to send and receive email during an outage and back up your data.
- With many SaaS solutions, there isn’t going to be a third-party service continuity option, but you might still be able to at least back up your data and implement business process workarounds to close the service gap.
Example SaaS risk and mitigation: O365
Risk
|
Options to mitigate risk (not an exhaustive list):
|
Example SaaS risk and mitigation: Salesforce
Risk
| Options to mitigate risk (not an exhaustive list):
|
Establish a baseline standard for risk mitigation, regardless of cloud service
At a minimum, set a goal to review vendor risk at least annually, define standard processes for monitoring outages, and review options to back up your SaaS data.
Example baseline standard for cloud risk mitigation
- Review vendor risk at least annually. This includes reviewing SLAs, vendor’s incident preparedness (e.g. do they have a current DRP, BCP, and Security IRP?), and the vendor’s data protection strategy.
- Incident response plans must include, at a minimum, steps to monitor vendor outage and communicate status to relevant stakeholders. Where possible, business process workarounds are defined to bridge the service gap.
- For critical data (based on your BIA and an evaluation of risk), maintain your own backups of SaaS data for additional protection.
Embed risk mitigation standards into existing IT operations
- Include specific SLA requirements, including incident management processes, in your RFP process and annual vendor review.
- Define cloud incident response in your incident management procedures.
- Include cloud data considerations in your backup strategy reviews.
Phase 3: Create an incident response plan
Phase 1 | Phase 2 | Phase 3 |
|---|---|---|
Assess your cloud risk | Identify options to mitigate risk | Create an incident response plan |
Activity 1: Review the example incident response workflows and case studies as a starting point
1-3 hours
|
Example SaaS Incident Response Workflow Excerpt 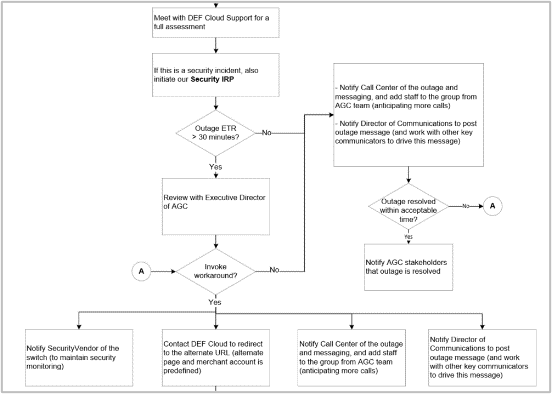 |
Materials |
|
||
| Participants | ||
|
Case Study 1: Recovery plan for critical fundraising event
If either critical SaaS dependency fails, the following plan is executed:
- Donors are redirected to a predefined alternate donation page hosted by a different service. The alternate page connects to the backup payment processing service (with predefined integrations).
- Marketing communications support the redirect.
- While the backup solution doesn’t gather as much data, the payment details provide enough information to follow up with donors where necessary.
Criticality justified a failover option
The Annual Day of Giving generates over 50% of fundraising for the year. It’s critically dependent on two SaaS solutions that host the donation page and payment processing.
To mitigate the risk, the organization implemented the ability to failover to an alternate “environment” – much like a traditional DR solution – supported by workarounds to manage data collection.
Case Study 2: Protecting customer data
Daily exports from a SaaS-hosted donations site reduce potential data loss:
- Daily exports to a CRM support donor profile updates and follow-ups (tax receipts, thank-you letters, etc.).
- The exports also mitigate the risk of data loss due to an incident with the SaaS-hosted donation site.
- This company is exploring more-frequent exports to further reduce the risk of data loss.
Protecting your data gives you options
For critical data, do you want to rely solely on the vendor’s default backup strategy?
If your SaaS vendor is hit by ransomware or if their backup frequency doesn’t meet your needs, having your own data backup gives you options.
It can also support business process workarounds that need to access that data while waiting for SaaS recovery.
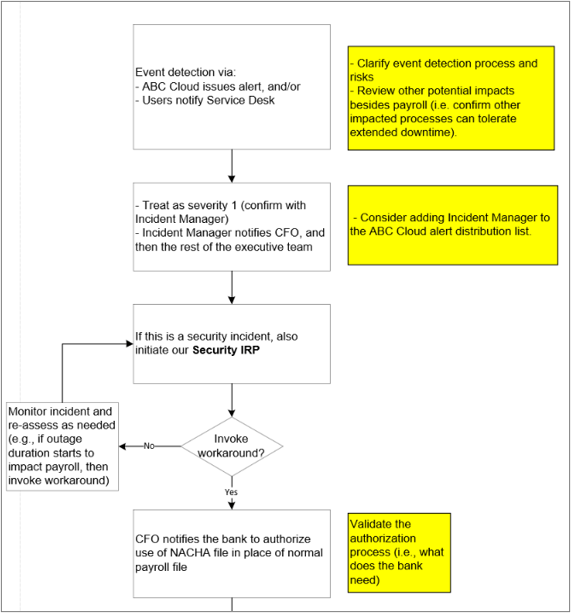
Case Study 3: Recovery plan for payroll
To enable a more accurate payroll workaround, the following is done:
- After each payroll run, export the payroll data from the SaaS solution to a secure location.
- If there is a SaaS outage when payroll must be submitted, the exported data can be modified and converted to an ACH file.
- The ACH file is submitted to the bank, which has preapproved this workaround.
BCP can bridge the gap
When leadership looks to IT to mitigate cloud risk, include BCP in the discussion.
Payroll is a good example where the best recovery option might be a business continuity workaround.
IT often still has a role in business continuity workarounds, as in this case study: specifically, providing a solution to modify and convert the payroll data to an ACH file.
Activity 2: Run tabletop planning exercises as a starting point to build your incident response plan
1-3 hours
|
Example tabletop planning results excerpt with gaps identified
|
Materials |
|
||
| Participants | ||
|
Activity 3: Summarize cloud services resilience to inform senior leadership of current risks and mitigation efforts
1-3 hours
|
Cloud Services Resilience Summary – Table of Contents |
Materials |
|
||
| Participants | ||
|
Summary: For cloud services, after evaluating risk, IT must adapt how they approach risk mitigation
- Identify failover options where possible
- A failover strategy is possible for many cloud services (e.g. IaaS replication to another region, or failing over SaaS to an alternate solution as in case study 1).
- Explore supplementary backup options to protect against ransomware, data corruption, or data loss and support business continuity workarounds (see case study 2).
- This doesn’t absolve IT of its role in mitigating cloud incident risk, but business process workarounds can bridge the gap where IT options are limited (see case study 3).
Related Info-Tech Research
Get an objective assessment of your DRP program and recommendations for improvement.
Create a Right-Sized Disaster Recovery Plan
Close the gap between your DR capabilities and service continuity requirements.
Develop a Business Continuity Plan
Streamline the traditional approach to make BCP development manageable and repeatable.
Implement Crisis Management Best Practices
Don’t be another example of what not to do. Implement an effective crisis response plan to minimize the impact on business continuity, reputation, and profitability.